Building Adaptive RAG using LangChain and LangGraph


The rise of Large Language Models (LLMs) has significantly improved AI-driven question-answering (QA) systems. However, traditional LLMs rely solely on their pre-trained data, which can lead to outdated or incorrect information. To address this limitation, Retrieval-Augmented Generation (RAG) is used. RAG integrates external knowledge sources, enhancing both accuracy and reliability.
However, basic RAG systems treat all questions the same, retrieving extra information even when it's unnecessary. This slows down simple queries and fails to provide enough depth for complex, multi-step questions.
To solve this problem, we use the Adaptive RAG technique, which dynamically adjusts the retrieval process based on the complexity of the query.
What is Adaptive RAG?
Adaptive RAG is a technique that adjusts retrieval depth based on query complexity and dynamically selects the optimal retrieval strategy. Unlike traditional RAG, which applies the same retrieval process to every query, Adaptive RAG operates in three distinct modes:
- No Retrieval Mode: Directly answers simple, fact-based questions using the LLM’s internal knowledge.
- Single-Step Retrieval Mode: Retrieves relevant external documents and incorporates them into the response generation process for moderately complex questions.
- Multi-Step Retrieval Mode: Iteratively retrieves multiple documents, integrating them into the reasoning process to answer complex, multi-hop questions.
This adaptive strategy creates a more efficient and scalable RAG pipeline, reducing unnecessary retrieval calls while maintaining high-quality responses.
Now, let's see the benefits of Adaptive RAG over Naïve RAG.
Benefits of Adaptive-RAG
Compared to traditional RAG approaches, Adaptive-RAG offers several distinct advantages:
| Feature | Naive RAG | Adaptive-RAG |
|---|---|---|
| Retrieval Strategy | Uses the same retrieval process for all queries | Adjusts retrieval based on query complexity |
| Efficiency | High computational overhead due to unnecessary retrievals | Optimized retrieval, reducing response time and costs |
| Accuracy | May retrieve irrelevant or excessive information | Provides precise, contextually relevant responses |
| Scalability | Struggles with varying query complexities | Easily adapts to different query complexities |
| Handling of Simple Queries | Applies retrieval even when not needed | Skips retrieval for simple queries, improving speed |
| Handling of Complex Queries | Limited ability to reason across multiple documents | Iteratively retrieves information for multi-hop reasoning |
| Hallucination Reduction | Higher risk of hallucinations due to excessive retrieval | Selective knowledge retrieval reduces hallucination risks |
Now that we understand the benefits of Adaptive RAG, it's time to move on to the implementation part.
For the complete code check out this Google Colab Notebook. Also, if you are interested in learning advanced or other Agentic RAG techniques, check out the GitHub repository we created.
Implementation of Adaptive-RAG
Let’s see how to build Adaptive-RAG using LangChain, LangGraph, OpenAI embeddings, FAISS, and Athina.
Step 1: Initial Setup
To begin, we need to install the required dependencies and set up API keys.
!pip install --q athina faiss-gpu langgraph
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
os.environ["TAVILY_API_KEY"] = userdata.get('TAVILY_API_KEY')
os.environ["ATHINA_API_KEY"] = userdata.get('ATHINA_API_KEY')
Step 2: Create a Vector Store
Next, we load the documents, split them into smaller chunks, and store them in a FAISS vector database for efficient retrieval.
from langchain_openai import OpenAIEmbeddings
from langchain.document_loaders import CSVLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
# Load embedding model
embeddings = OpenAIEmbeddings()
# Load data
loader = CSVLoader("./context.csv")
documents = loader.load()
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
documents = text_splitter.split_documents(documents)
# Create vectorstore
vectorstore = FAISS.from_documents(documents, embeddings)
retriever = vectorstore.as_retriever()
Step 3: Create a Web Search
Then, we integrate a web search tool using Tavily.
from langchain_community.tools.tavily_search import TavilySearchResults
# Define web search function
web_search_tool = TavilySearchResults(k=3)
Step 4: Question Router
After that, we create a Question Router, which determines whether a query should be answered using the vector database or a web search.
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["vectorstore", "web_search"] = Field(
..., description="Given a user question, choose to route it to web search or a vectorstore."
)
# LLM for routing decisions
llm = ChatOpenAI(temperature=0)
structured_llm_router = llm.with_structured_output(RouteQuery)
# Define routing prompt
system = """You are an expert at routing a user question to either a vectorstore or web search.
The vectorstore contains information on the following topics:
- Finance and real estate
- Library and research topics
- Biology and microbiology
- Literature and writing
- Movies and entertainment
- Animals and nature
- History and geography
- Astronomy
If the question is related to these topics, route it to the vectorstore. Otherwise, use web search."""
route_prompt = ChatPromptTemplate.from_messages([
("system", system),
("human", "{question}"),
])
question_router = route_prompt | structured_llm_router
Step 5: Document Grader
Then, we create a Document Grader, which will consider only useful and contextually accurate documents.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
class GradeDocuments(BaseModel):
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
llm = ChatOpenAI(temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
system = """You are a grader assessing relevance of a retrieved document to a user question.
If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant.
Give a binary score 'yes' or 'no'."""
grade_prompt = ChatPromptTemplate.from_messages([
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
])
retrieval_grader = grade_prompt | structured_llm_grader
Step 6: Answer Validation
After that, we validate whether the response is factually correct using a hallucination checker and a question relevance checker.
class GradeHallucinations(BaseModel):
binary_score: str = Field(description="Answer is grounded in the facts, 'yes' or 'no'")
hallucination_prompt = ChatPromptTemplate.from_messages([
("system", "You are a grader assessing whether an LLM generation is grounded in retrieved facts."),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
])
hallucination_grader = hallucination_prompt | structured_llm_grader
Step 7: Create and Build a Graph
Now, we create a graph-based workflow using LangGraph to connect all the steps we created above.
# define a data class for state
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
question: str
generation: str
documents: List[str]# define graph steps
from langchain.schema import Document
# all nodes
def retrieve(state):
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
def generate(state):
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}
def web_search(state):
print("---WEB SEARCH---")
question = state["question"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
return {"documents": web_results, "question": question}
# edges
def route_question(state):
print("---ROUTE QUESTION---")
question = state["question"]
source = question_router.invoke({"question": question})
if source.datasource == "web_search":
print("---ROUTE QUESTION TO WEB SEARCH---")
return "web_search"
elif source.datasource == "vectorstore":
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"
def decide_to_generate(state):
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.binary_score
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"# Build graph
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("web_search", web_search) # web search
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
# transform_query
# Build graph
workflow.add_conditional_edges(
START,
route_question,
{
"web_search": "web_search",
"vectorstore": "retrieve",
},
)
workflow.add_edge("web_search", "generate")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"generate": "generate",
},
)
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END
},
)
# Compile
app = workflow.compile()Step 8: Check the Output
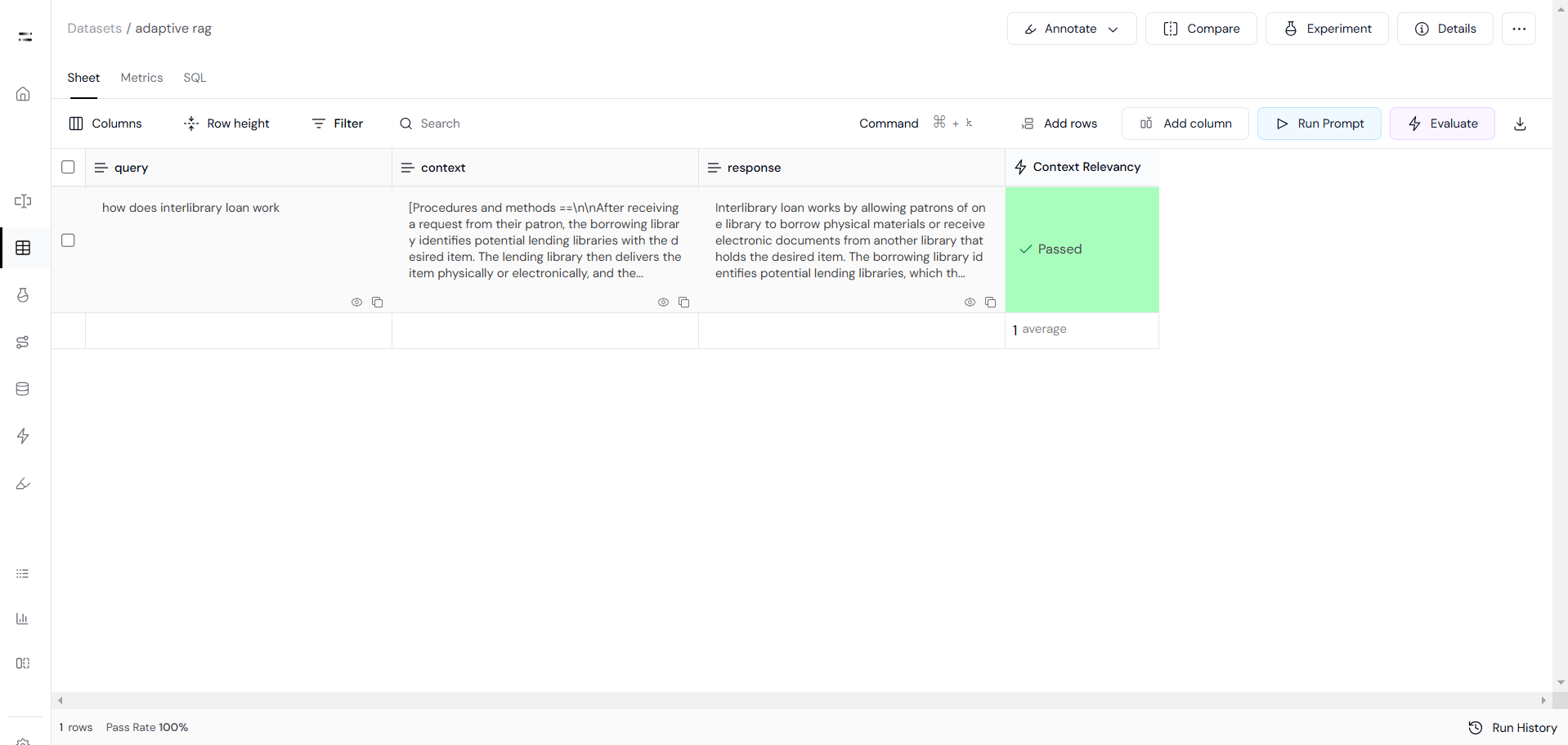
Test the Adaptive RAG pipeline using sample query as you can see below.
# Final generation example 1 (relevant documents)
from pprint import pprint
inputs = {"question": "how does interlibrary loan work"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Node '{key}':")
pprint("\n---\n")
pprint(value["generation"])Output:
---ROUTE QUESTION---
---ROUTE QUESTION TO RAG---
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'grade_documents':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
('Interlibrary loan works by allowing patrons of one library to borrow '
'physical materials or receive electronic documents from another library that '
'holds the desired item. The borrowing library identifies potential lending '
'libraries, and the lending library delivers the item either physically or '
'electronically. The borrowing library then receives the item, delivers it to '
'their patron, and arranges for its return if necessary. Fees may accompany '
'interlibrary loan services, and requests can be managed through '
'semi-automated or manual systems.')Step 9: Evaluation with Athina AI
First, we prepare the data by generating queries, capturing pipeline responses, and organizing the context for each query.
# Create a dataframe to store the question, context, and response
inputs = {"question": "how does interlibrary loan work"}
outputs = []
for output in app.stream(inputs):
for key, value in output.items():
if key == "generate":
question = value["question"]
documents = value["documents"]
generation = value["generation"]
# Combine document
context = "\n".join(doc.page_content for doc in documents)
# Append the result
outputs.append({
"query": question,
"context": context,
"response": generation,
})
# Convert to dictionary
df_dict = df.to_dict(orient='records')
# Convert context to list
for record in df_dict:
if not isinstance(record.get('context'), list):
if record.get('context') is None:
record['context'] = []
else:
record['context'] = [record['context']]Then, we use Context Relevancy evaluation to measure how relevant the retrieved information is to the question.
# set api keys for Athina evals
from athina.keys import AthinaApiKey, OpenAiApiKey
OpenAiApiKey.set_key(os.getenv('OPENAI_API_KEY'))
AthinaApiKey.set_key(os.getenv('ATHINA_API_KEY'))# load dataset
from athina.loaders import Loader
dataset = Loader().load_dict(df_dict)# evaluate
from athina.evals import RagasContextRelevancy
RagasContextRelevancy(model="gpt-4o").run_batch(data=dataset).to_df()The results will be converted into a data frame, and you can click on the generated link to open the Athina IDE, where you can explore detailed evaluation results and refine your pipeline further.
Conclusion
Adaptive RAG improves traditional RAG by adjusting retrieval based on query complexity, making simple queries faster and complex ones more accurate. We explored its key benefits, like better efficiency, scalability, and reduced hallucinations, and showed how to build it using LangChain, LangGraph, FAISS, and Athina AI.
To learn more advanced + agentic RAG techniques check out this GitHub repository.


