Building RAG with Unstructured Data

Retrieval-augmented generation (RAG) improves the large language model's (LLM) response by using external data to enhance the relevance and accuracy of their outputs. Instead of relying only on pre-trained knowledge, RAG allows models to fetch and integrate information from external sources, such as vector databases. This approach is particularly useful for tasks that require up-to-date or domain-specific information.
However, traditional RAG systems often struggle with unstructured data, data that does not follow a consistent format, such as PDFs containing tables, diagrams, and text. To overcome this, tools like Unstructured have been developed to extract clean text and meaningful segments from raw formats. This tool simplifies the process of handling unstructured data by breaking it into manageable pieces that can be used effectively in RAG pipelines.
In this blog, we will learn how to use Unstructured to process unstructured data efficiently, helping LLMs provide more accurate and relevant responses. To better understand how Unstructured helps, let's first look at the limitations of traditional RAG when dealing with unstructured data.
Drawbacks of Traditional RAG
Traditional RAG systems work well with structured data, which is organized and easy to retrieve. However, unstructured data is harder to process because it doesn’t have a consistent format. Extracting useful information from unstructured data often requires complex techniques, and the variety in formats and content makes retrieval and processing more difficult. This makes it challenging for traditional RAG systems to handle unstructured data effectively.
How Unstructured RAG Solve This Problem?
Unstructured (or semi-structured) RAG turns raw, unstructured data into a format that RAG systems can process. It uses advanced techniques to extract meaningful text and metadata from formats like PDFs, Word documents, and HTML files. It also organizes the data into clear sections, such as headings, paragraphs, and tables, ensuring consistency and making it easier to index and retrieve. By doing so, Unstructured streamlines the processing of unstructured data, allowing RAG workflows to handle it efficiently and effectively.
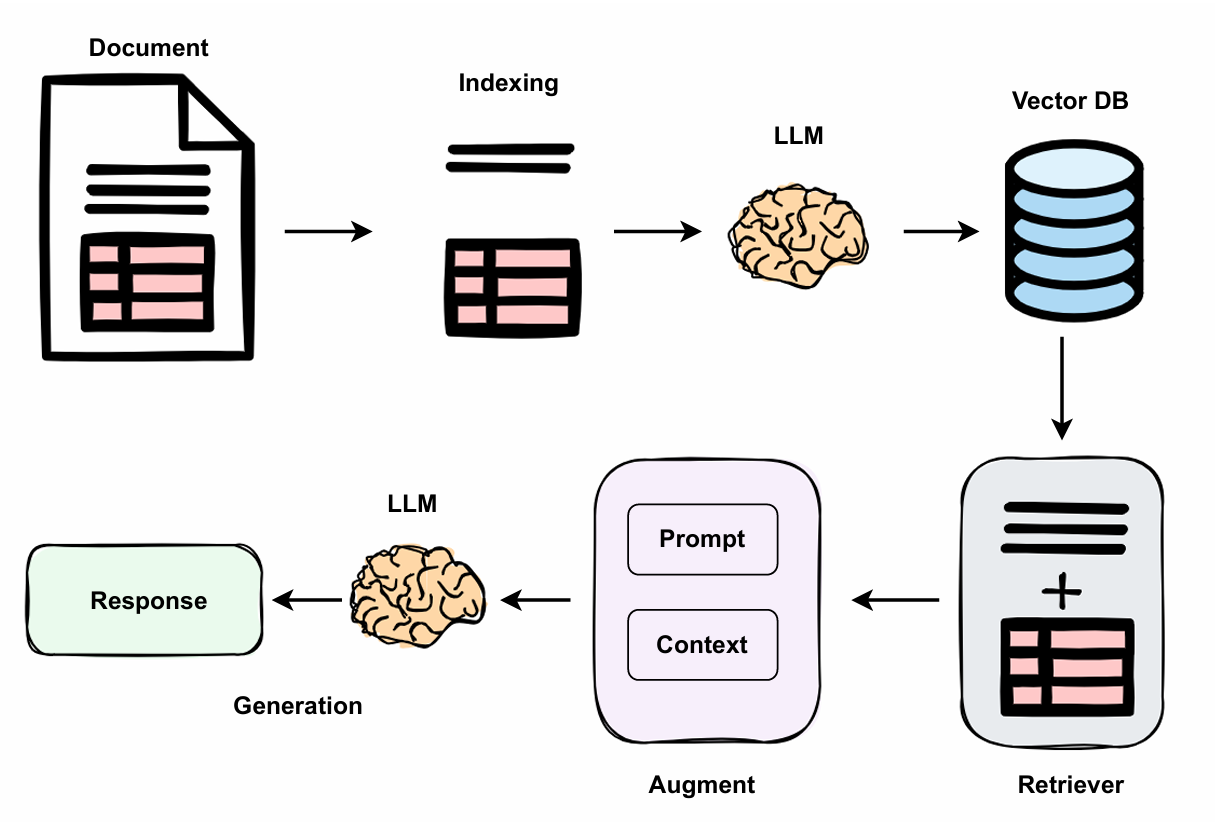
Now that we understand the limitations of traditional RAG and how Unstructured solves these problems, it's time to move on to the implementation part.
Implementation of Unstructured RAG
For the complete code and step-by-step guidance, check out this Google Colab Notebook. Also, if you are interested in learning advanced RAG techniques, check out the GitHub repository we created to support developers and researchers.
Demo by Author
Let's start by installing the required libraries:
! pip install --q athina faiss-gpu pytesseract unstructured-client "unstructured[all-docs]"
!apt-get install poppler-utils
!apt-get install tesseract-ocr
!apt-get install libtesseract-devAfter installing the libraries, set up your environment variables:
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
os.environ["ATHINA_API_KEY"] = userdata.get('ATHINA_API_KEY')
Then load the embedding model and process the PDF using to extract elements like images, tables, and text chunks:
# Load embedding model
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# Load and extract elements from PDF
from unstructured.partition.pdf import partition_pdf
filename = "/content/sample.pdf"
pdf_elements = partition_pdf(
filename=filename,
extract_images_in_pdf=True,
strategy="hi_res",
hi_res_model_name="yolox",
infer_table_structure=True,
chunking_strategy="by_title",
max_characters=3000,
combine_text_under_n_chars=200,
)
# Check unique categories
from collections import Counter
category_counts = Counter(str(type(element)) for element in pdf_elements)
unique_categories = set(category_counts)
# Extract unique types
unique_types = {el.to_dict()['type'] for el in pdf_elements}
# Convert elements to LangChain documents
from langchain.schema import Document
documents = [Document(page_content=el.text, metadata={"source": filename}) for el in pdf_elements]
After that, create a vector store using FAISS to store the document embeddings:
# Create vector store
from langchain.vectorstores import FAISS
vectorstore = FAISS.from_documents(documents, embeddings)Then, create a retriever from the vector store:
# Create retriever
retriever = vectorstore.as_retriever()
Finally, build the RAG pipeline with a LangChain LLM and custom prompt:
# Load LLM
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
# Create document chain
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
template = """
Answer the question based only on the following context, which can include text and tables.
Use the provided context to answer the question.
Question: {input}
Context: {context}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)
# Setup RAG pipeline
rag_chain = (
{"context": retriever, "input": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Get response
response = rag_chain.invoke("Compare all the Training Results on MATH Test Set")
print(response)
Evaluation in Athina AI
Once your RAG pipeline is set up, you can evaluate its performance using Athina AI. This step is optional but helpful for testing and validating your pipeline. Athina AI provides automated tools to measure accuracy and ensure the pipeline meets your requirements.
We will begin by preparing the data and then use Athina AI SDK for evaluation:
First, prepare your data by generating queries, capturing pipeline responses, and organise the context for each query:
# create dataset
question = ["Compare all the Training Results on MATH Test Set"]
response = []
contexts = []
# Inference
for query in question:
response.append(rag_chain.invoke(query))
contexts.append([docs.page_content for docs in retriever.get_relevant_documents(query)])
# To dict
data = {
"query": question,
"response": response,
"context": contexts,
}
# Convert context to list
for record in data:
if not isinstance(record.get('context'), list):
if record.get('context') is None:
record['context'] = []
else:
record['context'] = [record['context']]Now, setup API keys for both OpenAI and Athina:
from athina.keys import AthinaApiKey, OpenAiApiKey
OpenAiApiKey.set_key(os.getenv('OPENAI_API_KEY'))
AthinaApiKey.set_key(os.getenv('ATHINA_API_KEY'))
Then, use the Loader class from Athina to load your dataset in dictionary format:
from athina.loaders import Loader
dataset = Loader().load_dict(dataset_dict)Finally, run the DoesResponseAnswerQuery evaluation metric:
To learn more about this. Please refer to the Athina AI documentation page for further details.
from athina.evals import DoesResponseAnswerQuery
result_df = DoesResponseAnswerQuery(model="gpt-4o").run_batch(data=dataset).to_df()The results will be converted into a data frame, and you can click on the generated link to open the Athina IDE, where you can explore detailed evaluation results and refine your pipeline further.
Conclusion
In this blog, we learned how to enhance Retrieval-Augmented Generation (RAG) to handle unstructured data using tools like Unstructured, LangChain, and Athina AI. We discussed the challenges of traditional RAG systems, how to process unstructured data, and how to integrate it into a RAG pipeline.
We also walked through an optional step to evaluate your pipeline with Athina AI, ensuring accuracy and relevance.
I hope this guide helps you implement and refine your RAG workflows. If you want to explore more advanced RAG techniques, check out the GitHub Repository.


