How a leading healthcare provider built an AI-powered drug validation pipeline


Introduction
AI copilots assist medical practitioners by providing real-time guidance, supporting diagnosis with data-driven insights and personalized treatment recommendations.
Medical practitioners need to look at a lot of details about patients before prescribing the medication—like the patient’s medical history, current symptoms, and how new medications might interact with what the patient is already taking.
This is where AI co-pilots can make a big difference. They help doctors process all this information quickly and make better decisions for their patients.
In this case study, we’ll show you how we helped a major healthcare provider build an AI copilot that uses workflows to support doctors in validating medical prescriptions.
Problem
The mentioned healthcare provider wanted to build an AI copilot that could use information from multiple sources and use its reasoning to help medical practitioners make decisions.
They wanted this co-pilot to validate drugs prescribed by the doctors to patients.
This copilot uses AI workflow to connect and orchestrate several steps, such as:
- Making calls to Large Language Models (LLMs)
- Accessing third-party APIs
- Running intermediary code steps
- Extracting data
However, validating drug prescriptions is a complex process that involves analyzing patient's medical data and evaluating the effect of the prescribed drug to ensure accuracy and safety.
They found testing and optimizing this workflow to be challenging. It requires running experiments with different combinations of models, prompts, and retrieval systems to figure out what works best for their needs.
Drug Validation Workflow
Here’s a multi-step workflow designed by them to evaluate drug prescriptions:
- Input Collection: Takes in two inputs:
- Information about the patient, including their symptoms and medical history.
- The name of the drug prescribed by the practitioner.
- Drug Information Retrieval: Fetches details about the drug by searching the web and other trusted sources.
- Summary Generation: Creates a summary of the drug’s benefits and potential side effects.
- Safety Analysis: Analyzes the patient’s data alongside the drug information to determine if the medication is safe for the patient.
- Final Recommendations: Generates a summary with precautions and dosage recommendations tailored to the patient.
Replicating the Workflow as an AI Pipeline
Here’s a step-by-step guide to building and testing an AI pipeline for a similar drug validation workflow:
Note: The following is a sample pipeline designed to work with modified data.
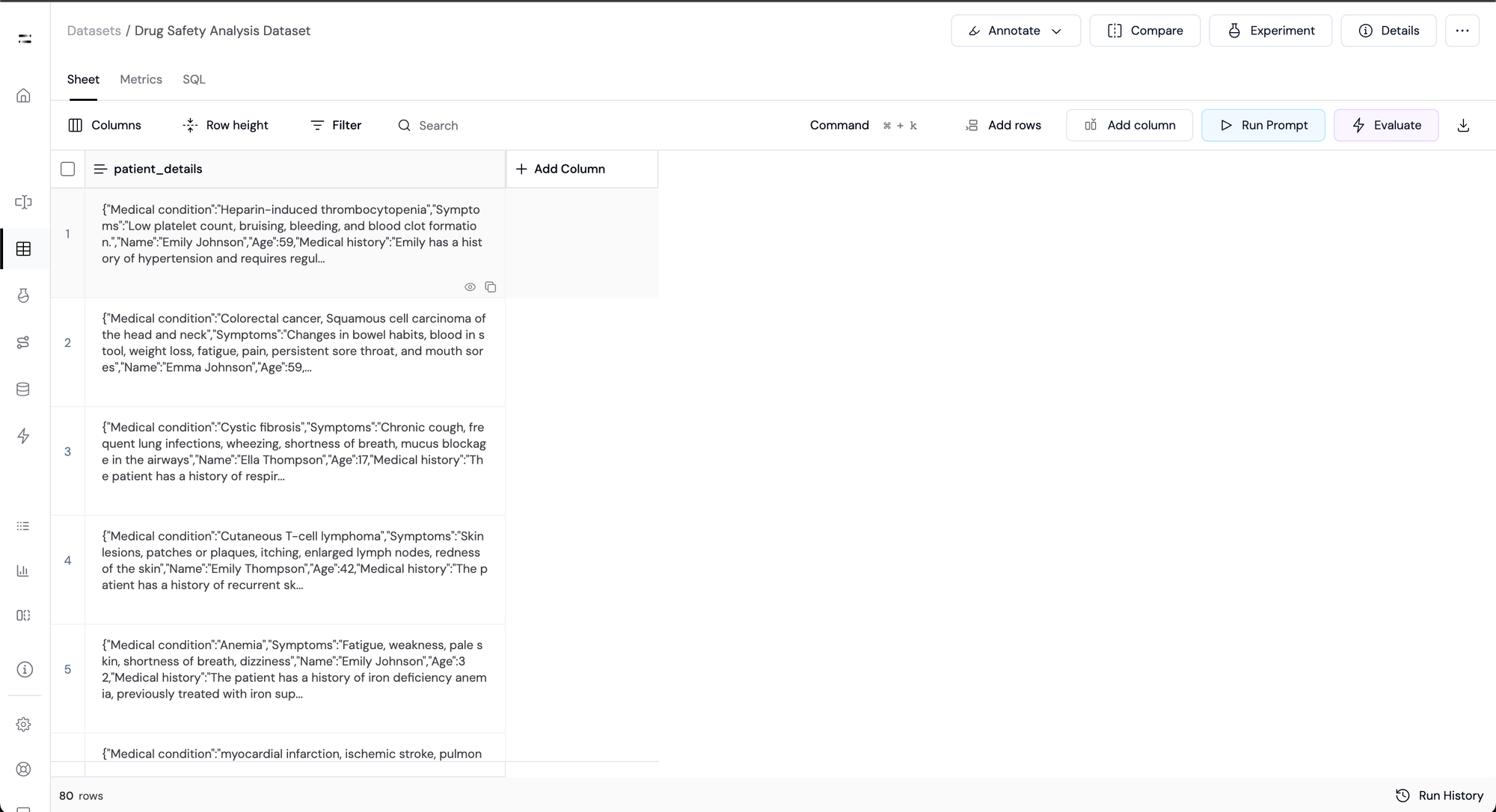
Step 1: Start with Patient Information
We start building the pipeline by uploading a dataset that contains patient information as a structured object. This includes patient details like - Name, age, medical condition, symptoms, and medical history.
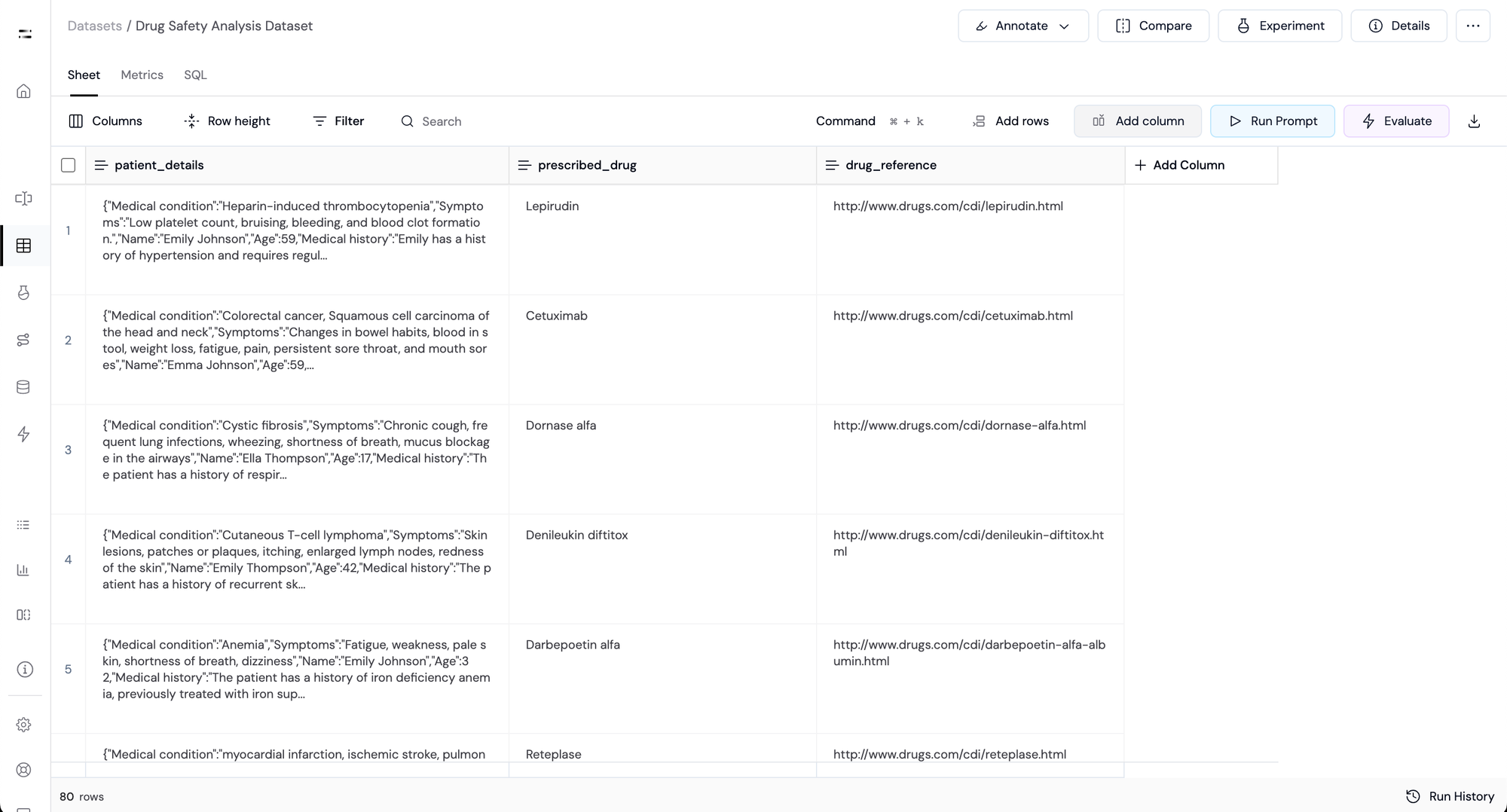
Step 2: Add Drug Information
Now we add information about the prescribed drug. This includes:
- Name of the prescribed drug in the column called
prescribed_drug. - A column named
drug_referencecontaining URLs with more detailed drug information.
Step 3: Fetch Drug Details:
Athina provides you with built-in functionalities that you can use to perform actions on existing columns and generate new columns (Dynamic Columns) based on those actions.
Here are the examples of the new columns you can generate
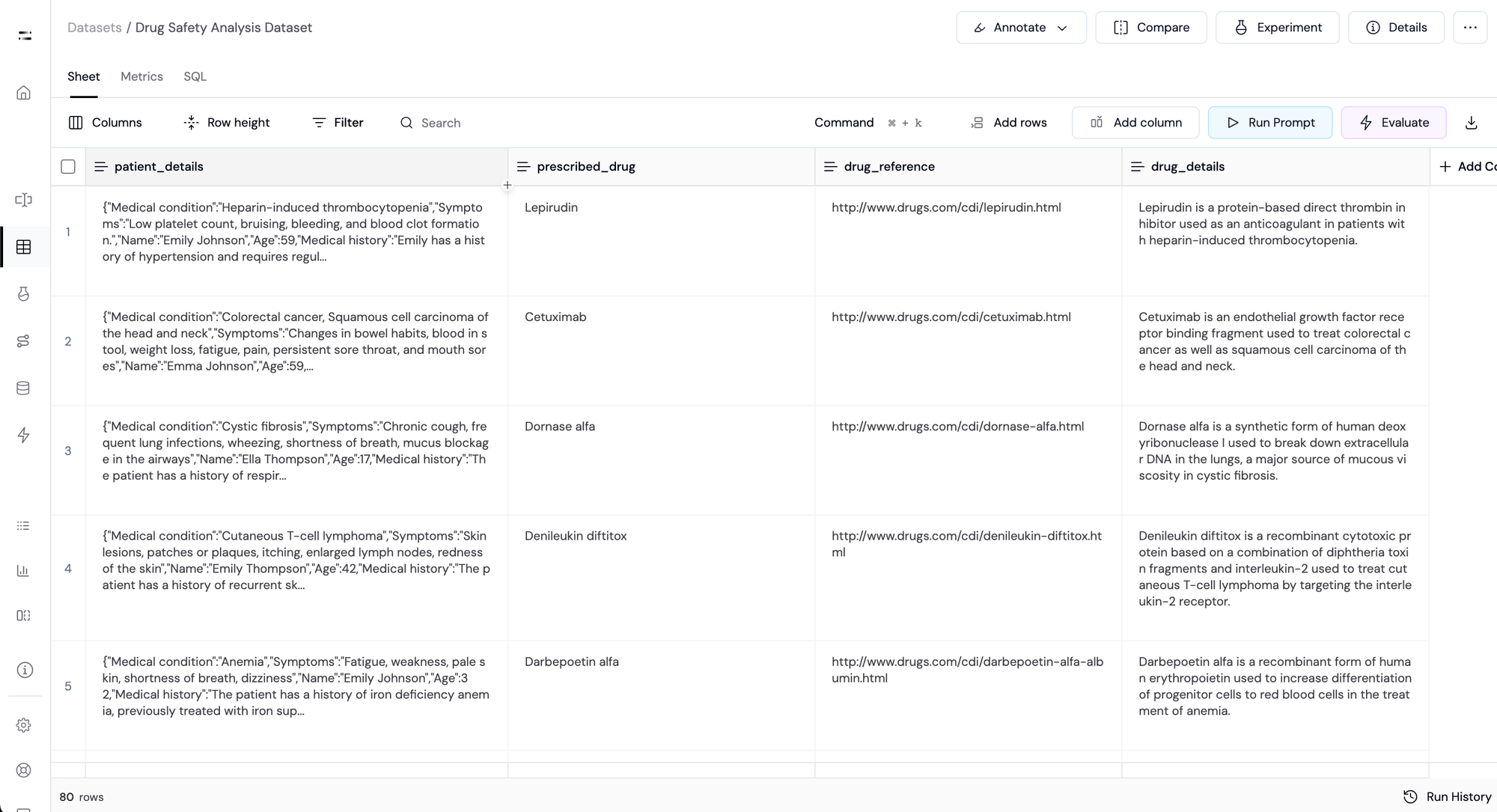
Next, we use the API call feature to create a dynamic column that pulls input from the drug_reference column and performs a web search to fetch concise information about the prescribed drug.
The result is added as a new column called drug_details
Step 4: Extract Medical History:
Next, we generate another dynamic column that uses the Extract JSON Key functionality.
This extracts information from the column patient_details containing the patient’s medical history as a JSON object.
This generates a new column called patient_medical_history
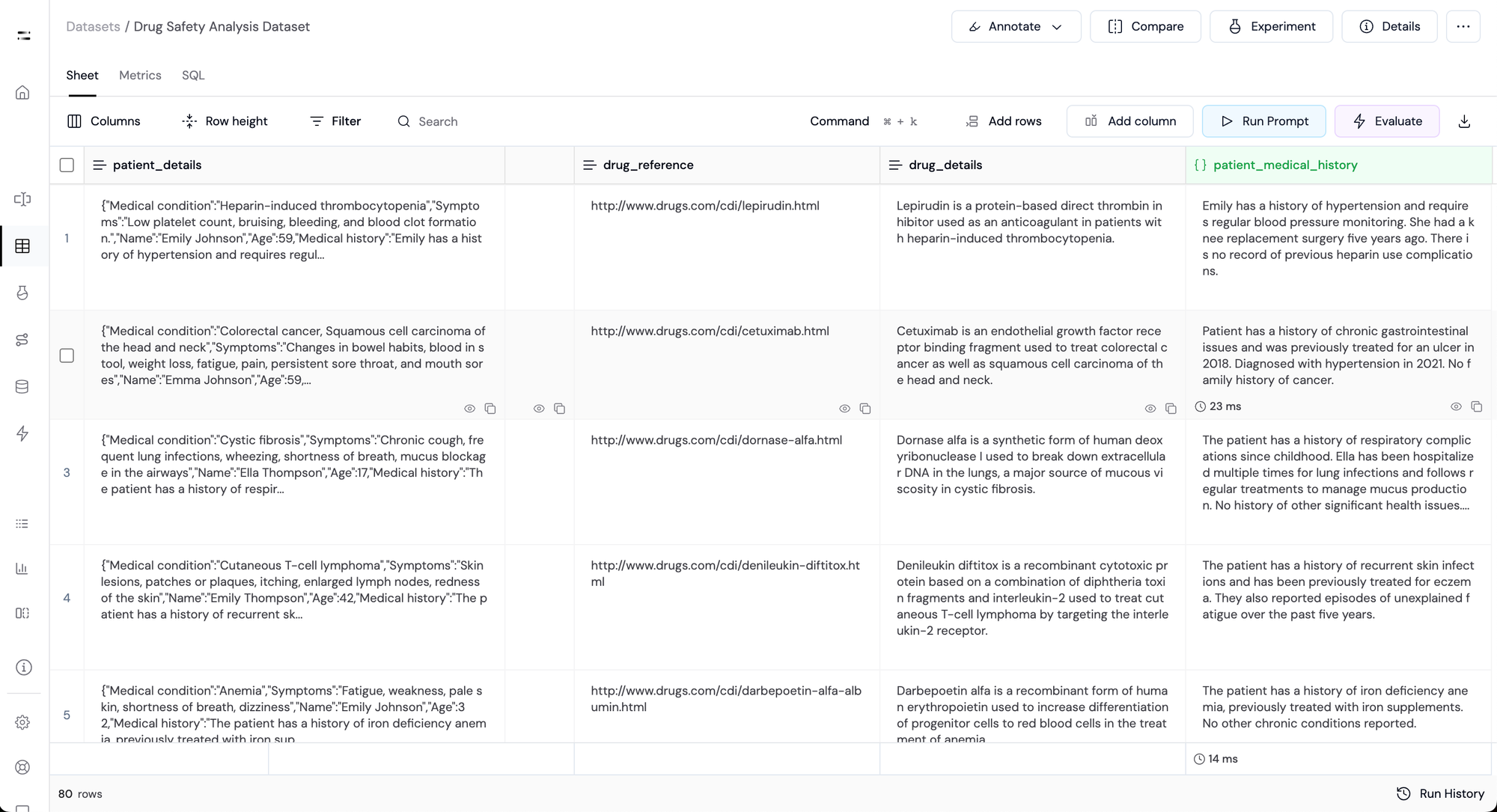
Step 5: Scrape Detailed Drug Data:
Now, we need to fetch more data about the prescribed drug. This will help us to understand the benefits and side effects of the medicine.
For this, we'll use the Firecrawl API to scrape the information from the provided URLs in the drug_reference column.

This generates a new dynamic column named drug_information containing the data scraped in Markdown format.
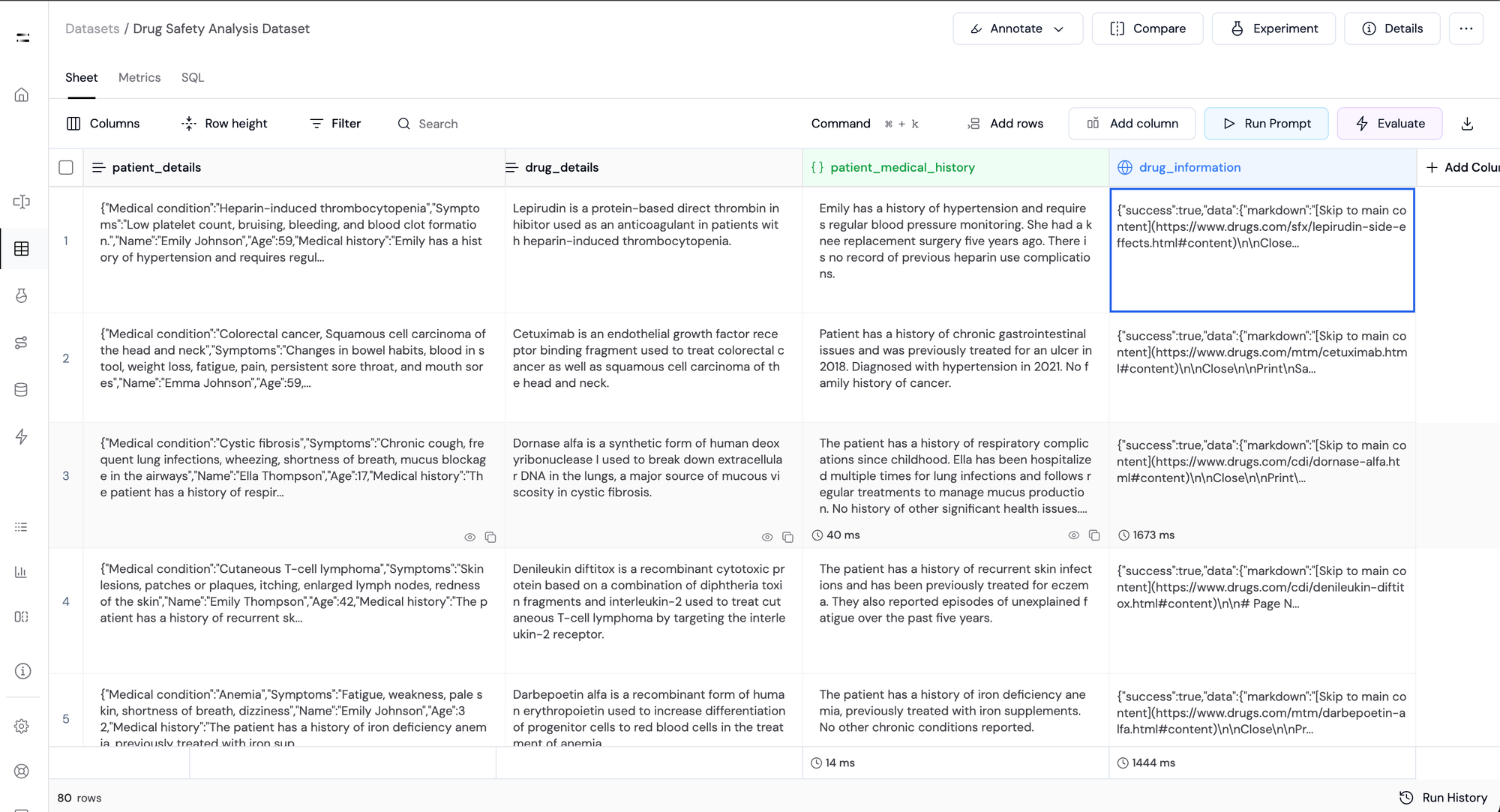
Step 6: Perform Safety Analysis with LLMs:
Next, we use an LLM to analyze the drug’s safety for the patient based on the patient's information and the drug's behavior.
For this, we'll prompt the model along with the following inputs :
drug_detailsdrug_informationpatient_medical_history
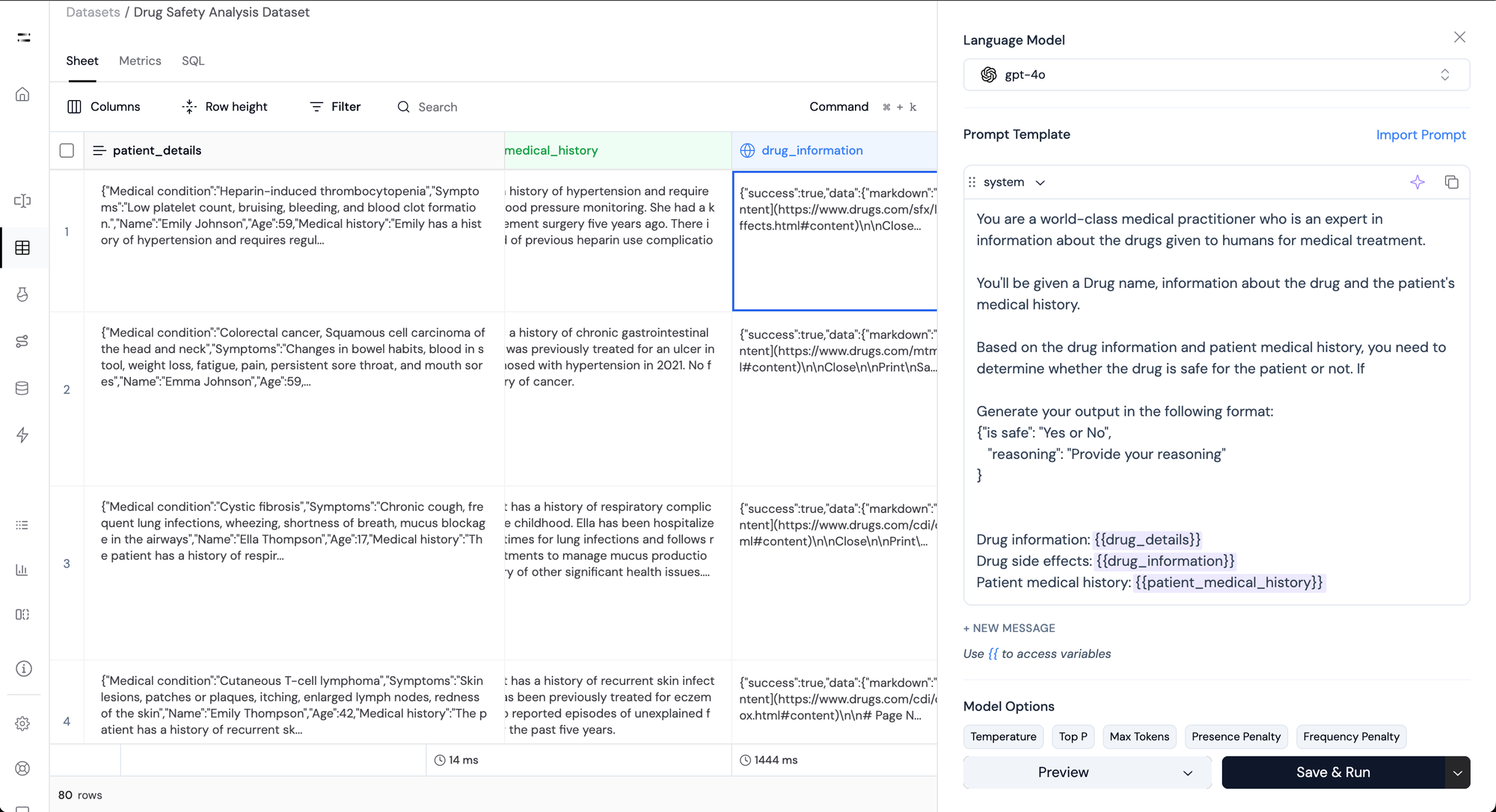
This generates a new column called drug_summary that contains information about whether the drug is safe for the patient or not and provides reasoning about the decision.
Athina also helps you leverage the structured output extraction functionality provided by models from Open AI and Gemini.
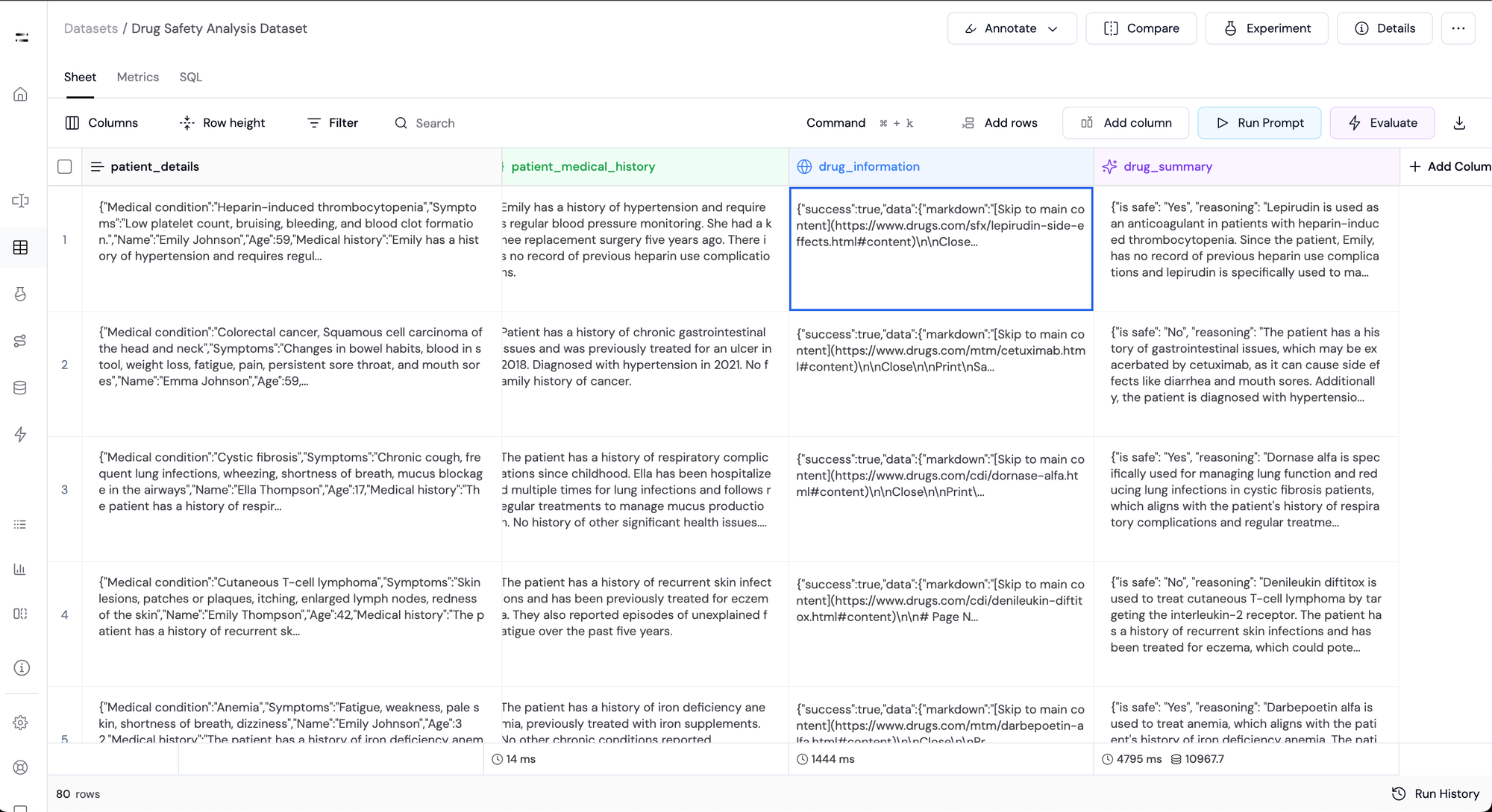
Step 7: Summarize Medication Details
Once we have the information about the medicine's suitability for the patient, we use another LLM to generate a summary that covers:
- Dosage recommendations
- Precautions for taking the medication
For this, we generate two more JSON extraction columns:
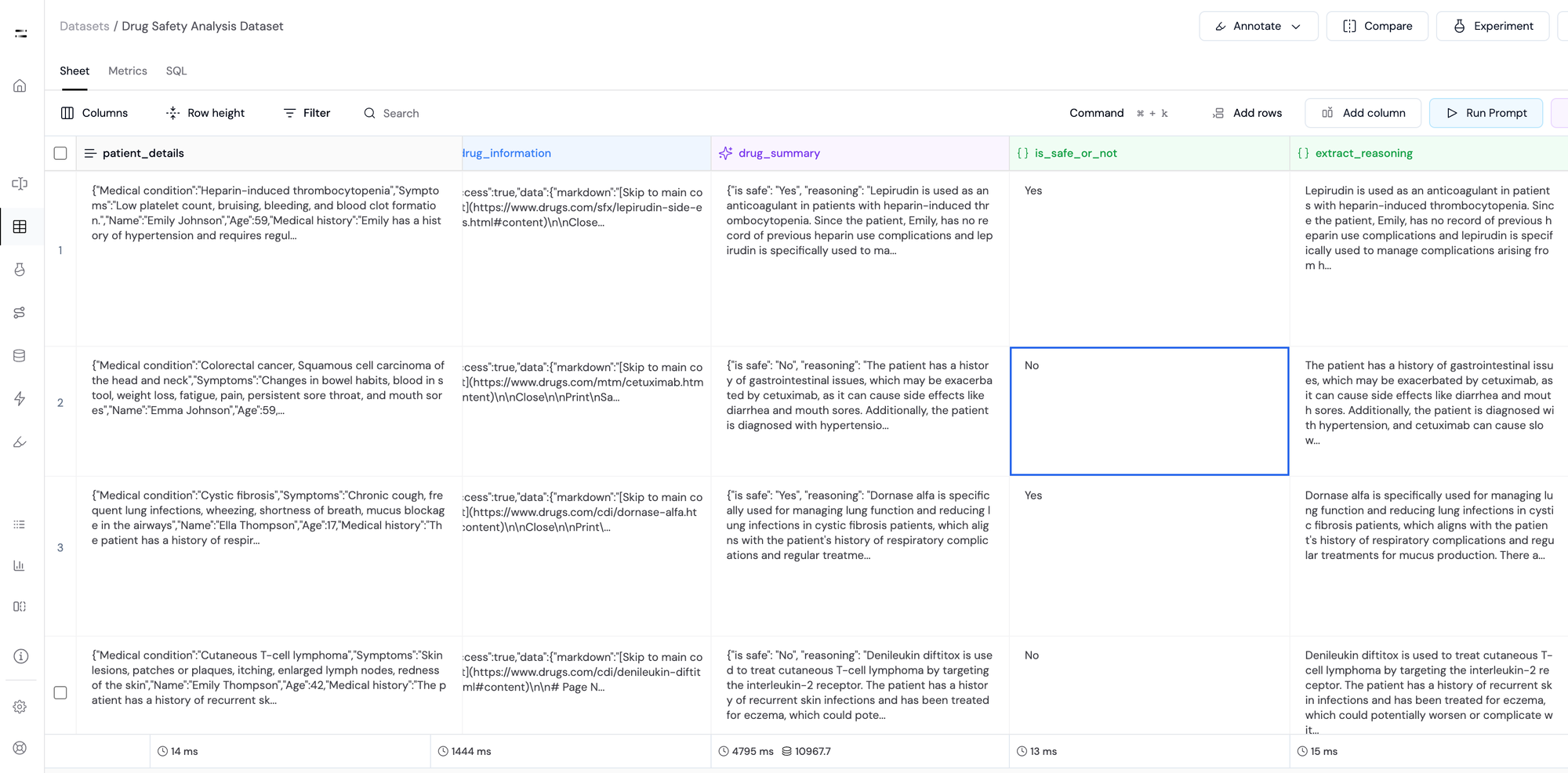
- A column
is_safe_or_notto extract the value of whether the drug is safe for the patient or not. - Another column
extract_reasoningto extract the reasoning of the model.
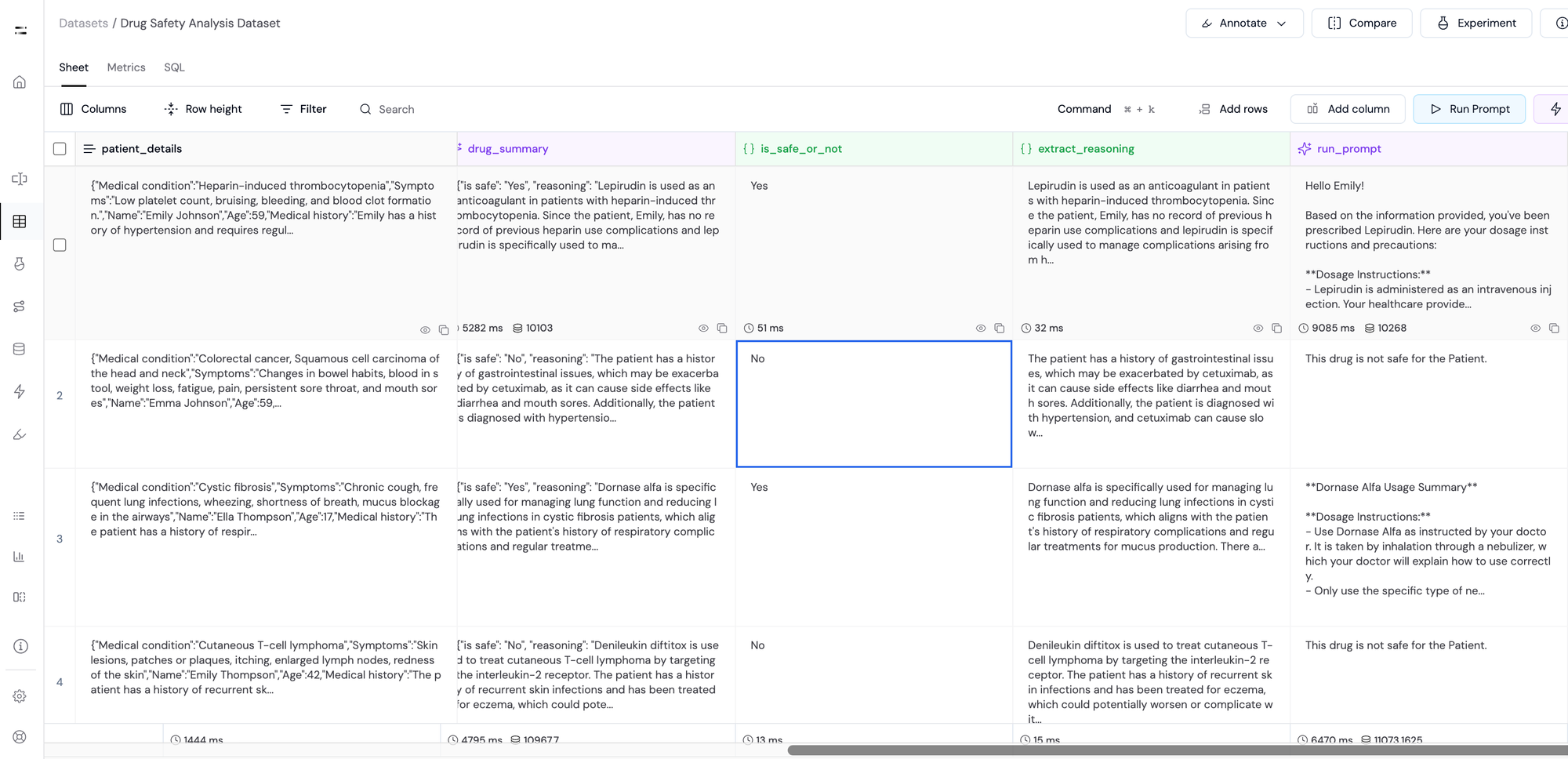
Now, the LLM generates a dosage and precaution summary only if the drug is safe for the patient. In case it is not, it generates a warning - "This drug is not safe for the patient".

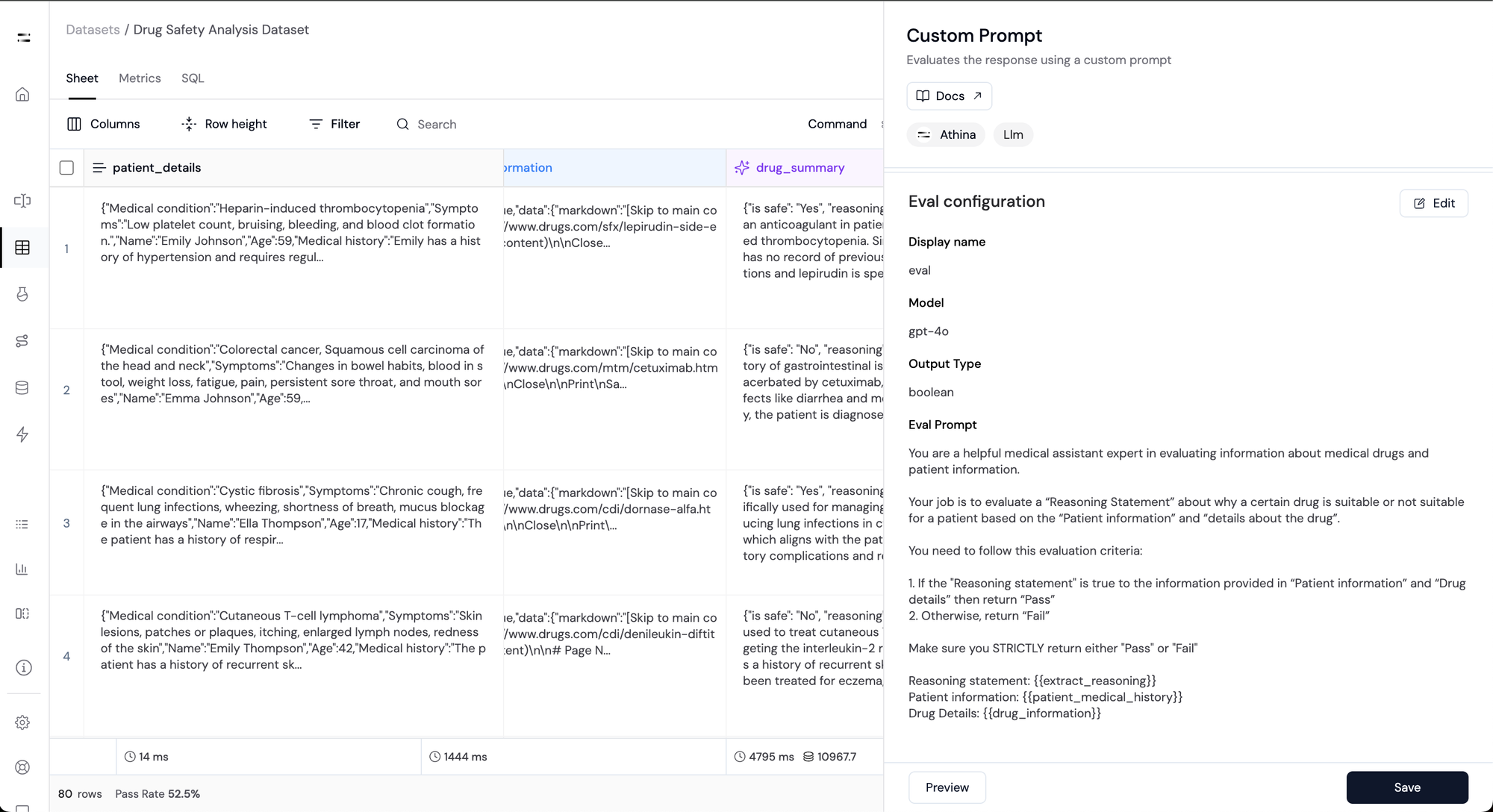
Step 8: Ensure Accuracy with Custom Evaluation
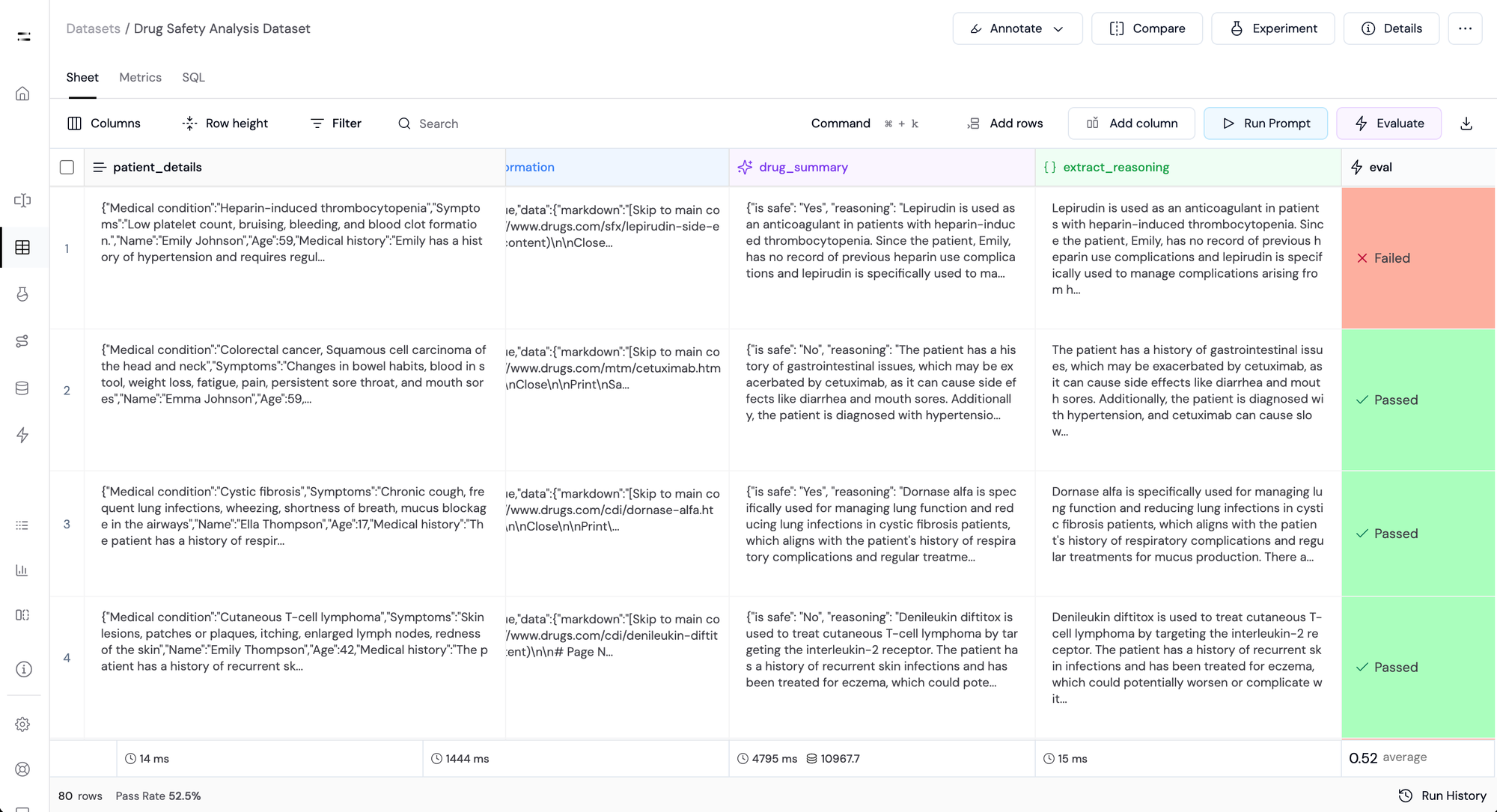
We can now check the quality of any generated dynamic column by using a custom evaluation.
Here we write a simple custom evaluation to check whether the reasoning generated by LLM in the drug_summary is factually correct or not.
Impact
By building and testing their AI pipeline on Athina, the healthcare provider was able to see a significant improvement in the performance and efficiency of their AI pipeline. Here’s what we achieved together:
- Faster Development: Reduced the workflow build time from 2 weeks to just 3 days, accelerating time to production.
- Improved Reliability: Boosted the accuracy of automated evaluations, increasing reliability scores from 52.5% to 89%
- Reduced Human Error: Lowered the human evaluation error rate from 15% to just 3%, ensuring more consistent outcomes.
- Enhanced Collaboration: Enabled seamless collaboration between product managers, data scientists, and domain experts, making the development process faster.
- Optimized Engineering Effort: Minimized engineering time by automating complex steps, allowing the team to focus on higher-value tasks.
In this case study, we demonstrated how to build an AI pipeline using Athina that contains multiple steps—like web search, data extraction, LLM reasoning, and custom evaluations—to create a reliable production-ready workflow.
With Athina, teams can build, test, and monitor such workflows seamlessly.
If you’re looking to implement a similar workflow or want to learn how our platform can help, feel free to reach out to us!


