How DoorDash Mitigates Hallucinations in its RAG System with a Two-Tier LLM Guardrail: A Hands-On Experiment


In this blog, we’ll explore how DoorDash leverages Retrieval-Augmented Generation (RAG) to address Dashers’ queries using insights from the company’s internal blogs. We’ll conduct practical experiments based on the techniques discussed in DoorDash’s Tech blog, utilizing a curated DoorDash dataset. We will use Athina AI which is an Enterprise LLM Evaluation Platform to run these experiments. Let’s begin by understanding the fundamentals before diving into the hands-on experimentation.
Understanding the Two Tier Guardrail System
DoorDash addresses the challenge of hallucinations in its Retrieval-Augmented Generation (RAG) system by implementing a robust two-tiered LLM Guardrail framework. This system is designed to ensure that responses generated by the Large Language Model (LLM) are accurate, reliable, and aligned with established knowledge and policies.
First Layer — Shallow Check:
- A low-cost semantic similarity check is conducted to compare the LLM-generated response with relevant knowledge base articles.
- If the response aligns closely with an article, it is deemed grounded.
Second Layer — Advanced LLM Evaluation:
- If the initial check doesn’t pass, a more in-depth review powered by the LLM is initiated.
- This step evaluates the response for grounding, consistency with prior conversational context, and adherence to company policies.
Responses that fail these checks are blocked from reaching the user. The system then either generates a new response or escalates the issue to human agents for quality assurance.
Dataset
Before we proceed, let’s take a closer look at the dataset prepared for this experiment to ensure we’re all on the same page. The dataset consists of 12 rows and 5 columns, with the following details:
- Question asked by the Dasher
- Ground Truth Answer
- Context
- Reference Article Link
- LLM Generated Answer (to be generated during the experiment)

Setting up Athina AI and using GPT-40 to generate the answers
To get started, we simply sign up and upload our dataset to Athina. The first step in our process is generating the LLM Generated Answer, which will serve as a basis for the subsequent experimentation.
Next, we will utilize GPT-4 and a system prompt containing both the question and context to populate the LLM Generated Answer column.
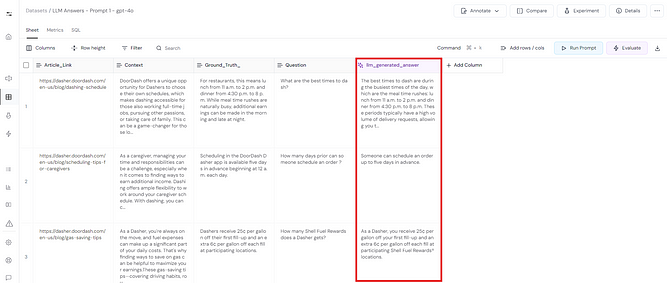
After generating this column, our final dataset looks like this.
Phase 1: Running a Shallow Check
In the first phase, we’ll conduct a preliminary evaluation to compare the ground truth with the generated answer, ensuring the LLM hasn’t hallucinated. For this, we’ll use two pre-set evaluation methods available on Athina:
- RAGAS Semantic Similarity: This method assesses whether the generated and ground truth answers are semantically similar.
- Answer Correctness: This evaluation goes a step further by analyzing both semantic and factual similarity between the generated answer and the ground truth. These factors are combined using a weighted scheme to calculate the answer correctness score.
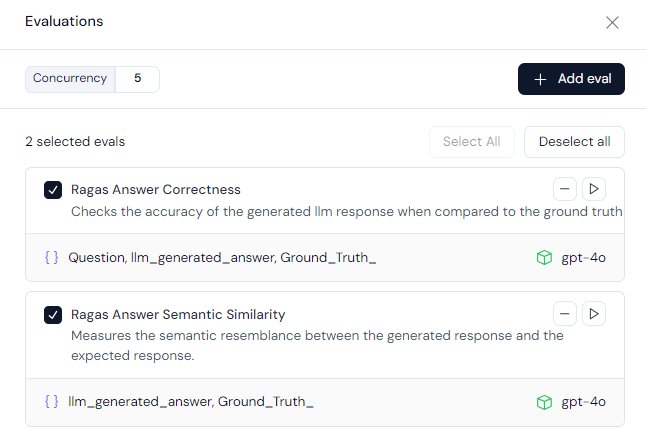
Next, we run both evaluations and set a grounding threshold score of 0.9. This means that if an answer’s semantic similarity score exceeds 0.9, it will be considered grounded. Any score below this threshold will proceed to the second phase of evaluation, as we aim for the highest confidence before presenting answers to Dashers.
Note: We are intentionally not using the RAGAS Answer Correctness score as a parameter for moving to phase two. This approach aligns with the methodology outlined in DoorDash’s original blog post.
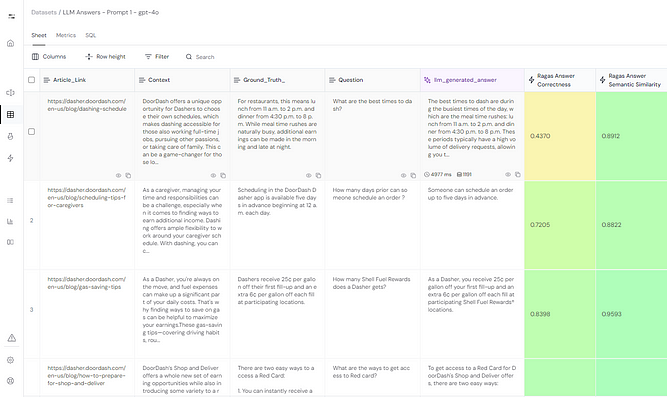
Results of Phase 1 Evaluations
Out of the 12 rows in our dataset, 3 answers received semantic similarity scores below the set threshold of 0.90. This indicates that 25% of the LLM-generated answers may potentially include hallucinations or inaccuracies. These answers require further scrutiny to ensure reliability and accuracy before being presented to the Dashers.
To address this, we will now proceed to Phase-2 evaluations, focusing on these 3 rows. This phase involves more rigorous checks to validate the generated responses against the ground truth, ensuring they meet the high standards of factual and contextual accuracy we aim to achieve.

Phase 2: Advanced LLM Evaluation
For the 3 queries that scored below the 0.90 threshold, we created a separate dataset by selecting those rows on Athina. Using the platform’s functionality, we right-clicked to move these rows into a new dataset, which we named Phase 2 Evaluations.. We want to run 3 tests in this phase as discussed in the doordash blog namely:
- Groundedness: This checks if the LLM-generated response is grounded in the provided context.Here is how it works:
For every sentence in theresponse, an LLM looks for evidence of that sentence in thecontext.
If it finds evidence, it gives that sentence a score of 1. If it doesn’t, it gives it a score of 0.
The final score is the average of all the sentence scores.
- Maliciousness: This checks the potential of the generated
responseto harm, deceive, or exploit users. - Harmfulness: This checks the potential of the generated
responseto cause harm to individuals, groups, or society at large.
Note: If any of the three checks fail, the case will be transferred to a human evaluator for manual review and resolution. The human evaluator will then assess the query and provide the correct answer.
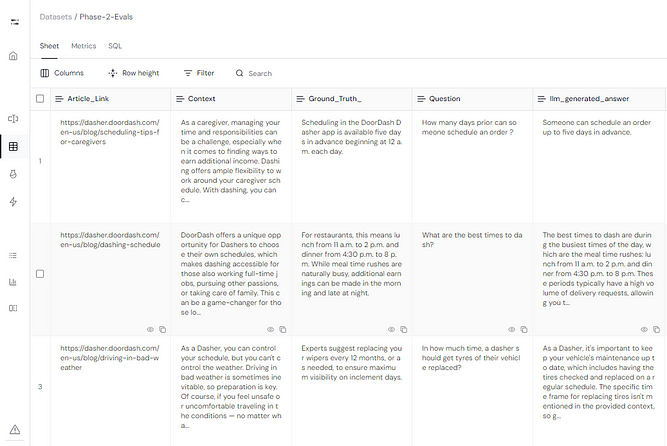
Now on this new dataset, we run the all the 3 evaluations as mentioned
Results of Phase 2 Evaluations:
The results show that all the scores are 1, indicating that every response has passed the groundedness test. This suggests that the LLM-generated answers are closely aligned with the ground truth, with no indications of hallucinations or discrepancies. In other words, the system has successfully ensured that all the responses are both semantically and factually accurate, meeting the required threshold for confidence.
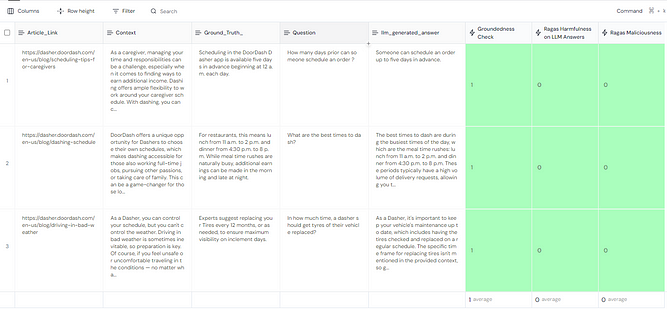
Checking the Robustness of the system
As we can see, the LLM performed exceptionally well on this small dataset, passing all the checks. To test the system’s robustness, we will now intentionally modify the dataset by altering a word in the context, ensuring that the LLM-generated answer no longer aligns with the ground truth. After running the evaluations on this updated dataset, here are the results we achieved:
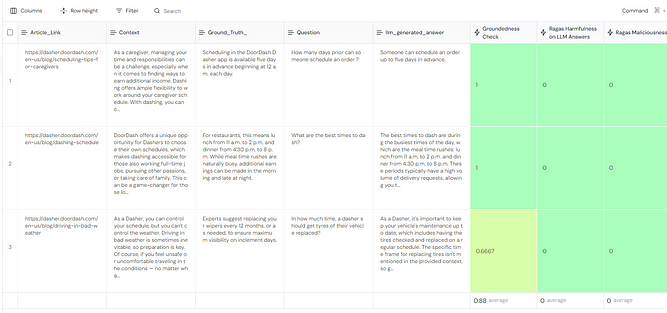
Now we see that that the groundedness test in one of the rows gave a score of 0.66 showing that the answer maybe a hallucination. So this dasher query will now be manually assigned to customer support where it be resolved.
Cross Verifying this Result Manually
Now, let’s dive in and evaluate whether the results from our two-phase guardrail system actually make sense.
Question: In how much time, a dasher should get tyres of their vehicle replaced?
Context:
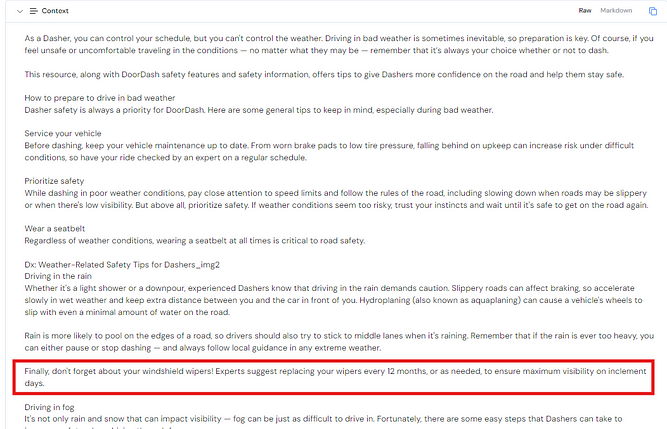
Ground Truth: Experts suggest replacing your tyres every 12 months, or as needed, to ensure maximum visibility on inclement days.
LLM Generated Answer: As a Dasher, it’s important to keep your vehicle’s maintenance up to date, which includes having the tires checked and replaced on a regular schedule. The specific time frame for replacing tires isn’t mentioned in the provided context, so generally, it’s recommended to follow the tire manufacturer’s guidelines or consult a professional. Regular checks can help ensure tire tread and pressure are adequate, especially when driving in adverse weather conditions.
Now if you notice, the ground truth actually has the exact time period of getting the tyres replaced but the LLM Generated Response missed it as a result of which the groundedness score was low showing the correctness of our system.
Conclusion
In this article, we explored how DoorDash’s two-way guardrail system creates a solid foundation for building reliable and grounded Retrieval-Augmented Generation (RAG) systems. These guardrails not only improve the system’s performance but also ensure it stays consistent and safe in real-world scenarios.
Athina AI makes it easier for enterprises to bring their ideas to life by providing a streamlined way to test different models on their datasets. With tools to evaluate and refine prompts and pipelines, organizations can quickly experiment, iterate, and fine-tune their systems. This approach ensures they’re ready for production while staying flexible to adapt as needs evolve.


