Implementation of Contextual Retrieval-Augmented Generation (RAG)


Finding and managing information has come a long way. We're drowning in data these days, and simply finding what we need isn't enough anymore. We need to understand how different pieces of information connect and what they mean together. This has forced us to get creative with how we organize and understand all this information.
One of the biggest breakthroughs has been RAG (retrieval-augmented generation). Think of RAG as combining a really smart search engine with AI that can write and explain things. It works by finding relevant information and weaving it into clear, accurate responses. This approach is much more reliable than older methods, since it bases its answers on real sources.
However, RAG systems face a major issue in maintaining contextual integrity during information retrieval. When extracting information from source materials, these systems often fail to capture the broader context that gives the data its full meaning. This limitation can result in responses that, while factually accurate, may lack the depth and nuance necessary for complete understanding. Without proper context, RAG systems risk providing incomplete or potentially misleading interpretations of complex topics.
This guide explores how contextual understanding is advancing RAG systems, covering key concepts, implementation approaches, and practical considerations for real-world applications.
Understanding Contextual RAG
Contextual RAG improves standard retrieval systems by maintaining and using document context throughout storage and retrieval processes. The system improves each piece of information by providing surrounding context, ensuring that retrieved data includes enough background for accurate interpretation and use.
A key component of this approach is contextual compression. This technique addresses the discrepancy between how information is stored and how it is used during query time.
Contextual compression improves the RAG system's focus on the most relevant data by filtering retrieved documents according to the specific query context. It extracts relevant passages and removes unnecessary information. This leads to more accurate and contextually appropriate responses.
Additionally, contextual RAG systems make use of contextual embeddings. This includes enriching document segments with concise summaries that encapsulate important background information. Usually generated by language models, these summaries improve semantic coherence and relevance during retrieval.
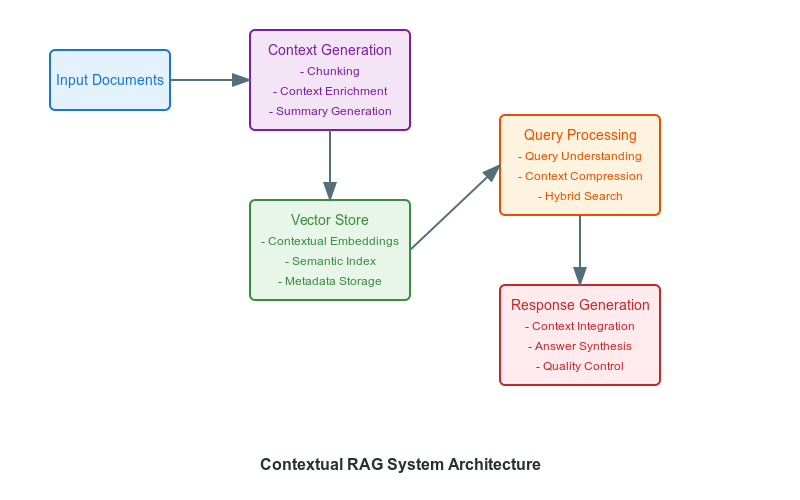
Key Components of Contextual RAG:
Contextual RAG systems usually employ the following components:
- Context Generation: A specialized module enhances each document segment with pertinent contextual data before embedding. This process ensures that the retrieved information is well-informed for accurate interpretation.
- Improved Embedding Mechanisms: Contextual RAG systems employ embedding mechanisms that encapsulate both the content and context. This leads to more accurate semantic representations.
- Contextual Embeddings: This method improves retrieval by adding customized contextual summaries before each document segment. This preserves document-level information within individual chunks and improves efficiency by reducing ambiguity during semantic analysis. For instance, language models generate concise summaries of 50-100 tokens, encapsulating essential background information.
Using these elements, contextual RAG systems significantly improve AI-generated responses' accuracy, relevance, and coherence.
Contextual Embeddings
Contextual embeddings transform document processing by integrating meaningful context before the embedding phase. This improves the granularity of semantic representation and retrieval accuracy.
Contextual embeddings improves semantic coherence and relevance in retrieval by prepending tailored contextual summaries to each document segment.
For instance, language models generate concise context summaries, typically spanning 50-100 tokens, which encapsulate essential background information.
This approach preserves important document-level information within individual chunks and improves computational efficiency by reducing ambiguity during semantic analysis.
Implementation: Building a Contextual RAG System
The following implementation guides you through setting up a Contextual RAG (Retrieval-Augmented Generation) system. It incorporates contextual compression to optimize retrieved documents and leverages hybrid search methods for efficient retrieval based on semantic relevance.
The step-by-step process includes:
- Installing required dependencies
- Setting API keys for OpenAI and Athina
- Loading and preprocessing data into manageable chunks
- Creating embeddings and storing them in a vector database
- Implementing contextual retrieval with compression
- Building the RAG pipeline to process queries and generate responses
- Testing the system with example queries
- Evaluating the system's performance and context relevancy using Athina AI
By following these steps, you can set up your own Contextual RAG system and experiment with different configurations and datasets.
Step 1: Install Dependencies
The system first installs all required Python libraries for building the RAG pipeline. These packages provide core functionality for document processing, embedding generation, and text retrieval.
# Install requirements
!pip install --q athina chromadb langchain openaiStep 2: Set API Keys
The code securely collects and stores API keys for OpenAI and Athina.
from getpass import getpass
OPENAI_KEY = getpass("Enter OpenAI API Key: ")
ATHINA_KEY = getpass("Enter Athina API Key: ")
import os
os.environ["OPENAI_API_KEY"] = OPENAI_KEY
os.environ["ATHINA_API_KEY"] = ATHINA_KEY
Step 3: Load and Preprocess Data
Load a dataset and split documents into smaller chunks while preserving context.
from langchain.document_loaders import CSVLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = CSVLoader("./context.csv")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
documents = text_splitter.split_documents(documents)This ensures raw data is converted into manageable chunks for efficient retrieval.
Step 4: Create Embeddings and Vector Store
Generate embeddings and store them in a vector database for semantic similarity search.
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)The vector store indexes document chunks, enabling efficient retrieval based on semantic relevance.
Step 5: Implement Contextual Retrieval with Compression
Build a retriever that incorporates contextual compression to optimize retrieved documents.
from langchain_openai import ChatOpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
retriever = vectorstore.as_retriever()
llm = ChatOpenAI()
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)The compression retriever eliminates irrelevant data, returning only query-relevant information.
Step 6: Build the RAG Pipeline
Create a pipeline to process queries and generate contextually enriched responses.
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
prompt_template = """
You are a helpful assistant that answers questions based on the following context.
If you don't find the answer in the context, just say that you don't know.
Context: {context}
Question: {input}
Answer:
"""
prompt = ChatPromptTemplate.from_template(prompt_template)
rag_pipeline = (
{"context": compression_retriever, "input": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)This integrates retrieval and compression with a language model for precise responses.
Step 7: Test the System
Run example queries to validate the pipeline's functionality.
query = "What is quantum entanglement?"
response = rag_pipeline.invoke(query)
print(response)
Output:
"Quantum entanglement is a phenomenon where particles remain interconnected, and the state of one affects the state of the other, regardless of distance."Step 8: Evaluate the System with Athina AI
After setting up your Contextual RAG pipeline, we'll evaluate its performance using Athina AI. This optional step helps validate your system's effectiveness by measuring context relevancy - how well retrieved contexts align with user queries, ensuring optimal information retrieval.
Let's walk through the evaluation process:
First, we'll prepare our evaluation dataset by generating test queries and collecting the corresponding responses and contexts:
query = "What is quantum entanglement?"
response = []
contexts = []
response.append(rag_pipeline.invoke(query))
contexts.append([doc.page_content for doc in compression_retriever.get_relevant_documents(query)])
data = {
"query": [query],
"response": response,
"context": contexts,
}
for record in data:
if not isinstance(record.get('context'), list):
if record.get('context') is None:
record['context'] = []
else:
record['context'] = [record['context']]
Next, we need to configure our evaluation environment by setting up the necessary API credentials:
from athina.keys import AthinaApiKey, OpenAiApiKey
OpenAiApiKey.set_key(os.getenv('OPENAI_API_KEY'))
AthinaApiKey.set_key(os.getenv('ATHINA_API_KEY'))Then, we'll load our prepared dataset using Athina's Loader class:
from athina.loaders import Loader
dataset = Loader().load_dict(data)Finally, we'll execute the Context Relevancy evaluation to assess our system's performance:
from athina.evals import RagasContextRelevancy
results = RagasContextRelevancy(model="gpt-4o").run_batch(data=dataset).to_df()The evaluation results will be presented in a data frame format, accessible through the Athina IDE via a generated link. This interface provides comprehensive visualization and analysis tools to help you understand your system's performance and identify potential areas for improvement. The Context Relevancy metric specifically helps you understand how well your system maintains semantic coherence between queries and retrieved contexts, ensuring that your RAG pipeline delivers accurate and contextually appropriate responses.
Conclusion
In conclusion, Retrieval-Augmented Generation (RAG) systems have transformed how we handle and understand large amounts of data. By adding context through techniques like contextual compression and embeddings, these systems make AI responses more accurate, relevant, and clear.
This guide showed how to build a Contextual RAG system step by step, from processing data to evaluating performance. Tools like Athina AI help ensure the system retrieves the right information and stays aligned with user queries.
Contextual RAG is a big step forward, making it easier to connect and understand complex information. As these systems improve, they’ll help us find better answers and make sense of the overwhelming amount of data we deal with today.


