LLMOps Part 1: Introduction

The world is experiencing a transformative wave driven by large language models (LLMs). These advanced AI models, capable of understanding and generating human-quality text, are changing interactions with technology and information.
LLMs power various applications, from chatbots and virtual assistants to content creation tools, advanced search engines, and even personalized recommendation systems.
As more organizations integrate LLMs into their products and services, a new operational framework is emerging: LLMOps (Large Language Model Operations).
It provides the infrastructure needed to bring LLM to life, ensuring they are reliable, scalable, and aligned with business objectives.
LLMOps is a specialized discipline focused on the development, deployment, and management of LLMs in production environments.
It includes a set of practices, techniques, and tools that streamline the process of building, deploying, monitoring, and governing these advanced AI models.
While LLMOps build upon the foundations of MLOps (Machine Learning Operations), they introduce a distinct set of considerations.
These include prompt engineering, continuous evaluation, and monitoring for responsible and effective use.
Advantages of Adopting LLMOps
The transformative potential of LLMs is more than merely theoretical. A recent survey of 70 AI industry leaders across various sectors found that nearly 80% of the enterprise market share is dominated by closed-source LLMs, with a significant portion attributed to OpenAI.
This shows the increasing dependence on LLMs and the need for robust operational practices to manage them effectively.
Furthermore, research by Hugging Face indicates that LLMOps can lead to significant cost savings compared to relying on cloud-based LLM services.
Fine-tuning a smaller, open-source LLM (like Gemma 7B) using an LLMOps pipeline (LlamaDuo) resulted in substantially lower operational costs over time than a service like GPT-4o through its API.
This is particularly relevant for organizations with long-term LLM deployments where continuous API usage can become prohibitively expensive.
The adoption of LLMOps provides numerous benefits for organizations seeking to leverage the power of LLMs:
- Accelerated Development Cycles: LLMOps promotes automation and collaboration, speeding up experimentation and iteration. This leads to quicker development cycles and reduced time-to-market for LLM-powered applications. It also allows developers to focus on innovation and model improvement by automating repetitive tasks and providing standardized workflows.
- Enhanced Model Performance: LLMOps is a structured approach to data management, model training, and evaluation that ensures LLMs are trained on high-quality data and optimized for specific tasks. This leads to improved accuracy, reliability, and overall performance.
- Increased Scalability: LLMOps frameworks facilitate the efficient deployment and scaling of LLMs, enabling organizations to handle growing volumes of data and user requests. This ensures that LLM-powered applications can meet the demands of real-world scenarios.
- Reduced Operational Costs: LLMOps can help lower the operational costs associated with managing LLMs by automating tasks and optimizing resource utilization. This makes LLM more accessible and cost-effective for organizations of all sizes and allows them to be used for various applications, from customer service and marketing to product development and research.
- Governance and Compliance: LLMOps provide a framework for establishing clear governance policies and ensuring compliance with regulatory requirements. This is crucial for mitigating risks associated with bias, fairness, and responsible AI development.
Complexities in Implementing LLMOps
Implementing and managing LLMs in a production environment can be challenging due to their complexity, requiring careful consideration and robust solutions.
The transition from proof-of-concept (PoC) development using service LLMs to model deployment often leads to reduced prompt effectiveness due to model discrepancies, resulting in negative user experiences.
This shows the need for efficient deployment strategies and carefully considering various factors impacting their performance, reliability, and ethical implications.
Here are some challenges that organizations must address when implementing LLMOps:
- Data Management at Scale: LLMs require massive amounts of high-quality training data. Collecting, cleaning, and managing this data can be challenging, especially given the need to address issues like bias, privacy, and intellectual property rights. Data quality, consistency, and provenance are essential for building reliable and trustworthy LLMs.
- Computational Resource Demands: Training and deploying LLMs often require significant computational resources, including specialized hardware and software. This can pose challenges for organizations with limited infrastructure or budgets.
- Model Explainability and Interpretability: Understanding how LLMs arrive at their outputs can be difficult due to their complex architecture. This lack of transparency can hinder trust and complicate debugging or improving models. Developing techniques for interpreting and explaining LLM behavior is crucial for building trust and ensuring responsible AI development.
- Continuous Monitoring and Feedback: LLMs can exhibit unexpected behaviors or biases, demanding continuous monitoring and feedback mechanisms to ensure they remain aligned with desired outcomes. Establishing monitoring systems and feedback loops is essential for maintaining LLM performance and mitigating potential risks.
LLMOps vs. MLOps
While LLMOps share core principles with MLOps, the unique characteristics of large language models (LLMs) require a specialized operational approach.
Both aim to streamline the AI model lifecycle, but LLMOps address the challenges of deploying and maintaining models like GPT and BERT.
MLOps focuses on optimizing machine learning models across diverse applications, whereas LLMOps tailors these practices to meet the complexities of LLMs.
How is LLMOps Different from MLOps
Model Complexity
LLMOps deals with models like GPT-3, which contains billions of parameters, compared to traditional ML models, which contain fewer model parameters.
This scale demands specialized hardware (GPUs/TPUs) and extensive computational resources, making training and fine-tuning more complex and resource-intensive.
Data Requirements
The size and scope of LLMs also affect their data requirements. While MLOps typically works with relatively structured task-specific datasets, LLMOps deals with large volumes of diverse and often unstructured text data from multiple sources.
For example, an LLM like GPT-3 is trained on datasets scraped from the internet, including books, articles, and websites, to develop a broad understanding of language.
Infrastructure
LLMOps demand robust infrastructure due to the computational demands of LLMs. Training large models requires distributed architectures and clusters of high-performance GPUs or TPUs.
Moreover, the energy and time needed to train these models are significantly higher than what’s typically encountered in MLOps workflows.
In MLOps, most models can be efficiently trained on standard cloud-based infrastructure or local servers.
Model Training and Fine-Tuning Cycles
While traditional MLOps involve regular model retraining, the fine-tuning cycles in LLMOps are considerably more iterative and complex.
Pre-trained LLMs (foundation models) are the base for fine-tuning and adapting them to specific tasks or domains, and this includes refining not just the model weights but also the prompt engineering strategies.
This iterative process of adjusting prompts and evaluating responses is important for optimizing the LLM's performance and achieving desired outcomes.
Deployment Complexity
LLMOps introduces new deployment challenges not commonly seen in MLOps. Deploying LLMs often requires using specific strategies, such as quantization or model compression, to reduce the model's size while maintaining accuracy.
Quantization reduces the number of bits used to represent model weights, allowing the model to run efficiently on hardware-constrained environments like edge devices.
Traditional machine learning models in MLOps do not typically require this optimization level unless deployed in specific environments, such as mobile applications.
Additionally, LLMs require more advanced deployment orchestration, as the large memory and compute requirements mean that more than traditional server configurations may be required.
LLM-Specific Considerations
Learning from Foundation Models and Fine-tuning
One key characteristic of LLMOps is its reliance on foundation models—large pre-trained language models that have learned general language representations from extensive text data.
Instead of training models from scratch, LLMOps fine-tunes these foundation models for specific tasks, offering several advantages.
- Reduced training time and resources: Fine-tuning requires less data and computation than training from scratch.
- Improved performance: Foundation models provide a strong starting point, leading to faster convergence and better performance on downstream tasks.
- Increased accessibility: Fine-tuning allows organizations to leverage the power of LLMs without the need for massive datasets or computational infrastructure.
Prompt Engineering for Tuning LLM Performance
Prompt engineering is essential in LLMOps to guide LLMs in producing desired behaviors. A well-created prompt provides clear instructions, optimizing the model's performance and ensuring it generates accurate and relevant responses.
This includes:
- Understanding prompt structure and design: Prompts can include instructions, context, examples, or questions to steer the LLM's generation process.
- Experimenting with different prompt formats: Different tasks may require different prompt styles, such as few-shot prompting, chain-of-thought prompting, or retrieval-augmented generation.
- Iteratively refining prompts: Analyzing LLM responses and iteratively adjusting prompts is essential for improving accuracy and aligning with user expectations.
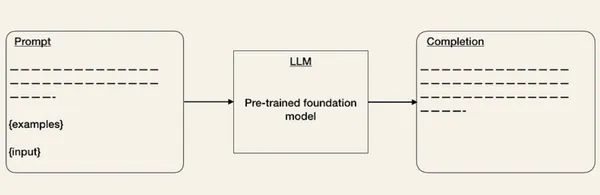
Prompt Engineering | Source
In the next part, we will see how the LLMOps workflow works


