LLMOps Part 2: Workflow and Model Development


Managing large language models (LLMs) through LLMOps workflows requires a structured approach to ensure effective development, deployment, and maintenance.
These workflows are divided into several key phases: data collection, model development, deployment, and governance, each crucial to the performance and sustainability of LLM systems. Specific methodologies, tools, and best practices are applied at every stage to optimize the operational efficiency of large-scale models.
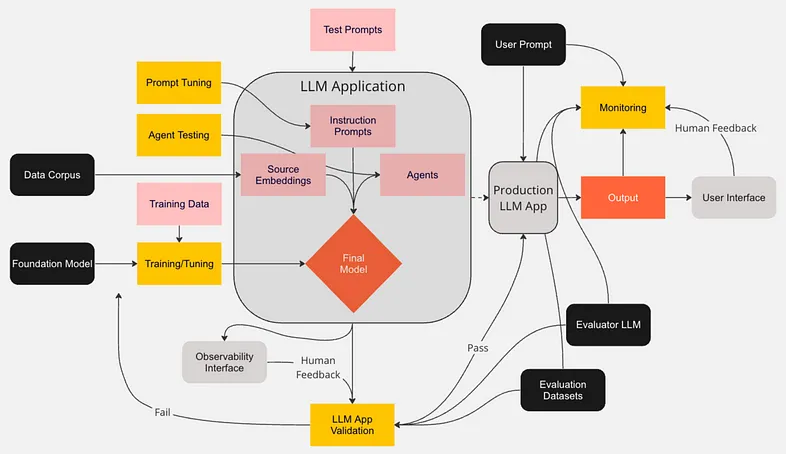
LLMOps Workflows | Source
Model Development
Model development forms the core of LLMOps workflows, covering data collection, preparation, training, fine-tuning, and evaluation. Each stage is important in defining the LLM's capabilities, optimizing performance, and addressing ethical considerations like bias and fairness.
Data Collection and Preparation
LLMs require vast amounts of diverse, high-quality data to understand the complexities of language effectively. The performance and accuracy of an LLM are highly dependent on the quality and variety of the input data.
This phase includes sourcing relevant datasets, cleaning and preprocessing the data, and augmenting the dataset to ensure it is comprehensive and aligned with the intended application.
Data Sources
Data collection for LLMs generally includes techniques like web crawling, API-based data, and pre-curated datasets like Hugging Face Datasets. These methods help gather the large amounts of unstructured data required for LLM training.
Web crawling allows for extracting diverse text sources, including articles, blogs, social media posts, and forums. Meanwhile, API-based collection can pull more structured data from platforms like Reddit or Wikipedia.
Additionally, pre-curated datasets from Hugging Face simplify the collection process by providing high-quality, ready-to-use data designed for LLM training.
Data Cleaning
Cleaning collected data is critical in preparing high-quality datasets for LLMs. Raw data often contains noise, inconsistencies, and irrelevant information, negatively impacting model performance.
Effective data cleaning techniques include:
- Deduplication: Removing duplicate or redundant text to avoid skewed results.
- Filtering: Excluding irrelevant or out-of-scope data that does not align with the target task or domain.
- Normalization: Standardizing text formats by converting text to lowercase, removing special characters, and unifying formats for dates, numbers, or currencies to improve consistency in processing.
- Error Correction: Fix syntax errors and handle incomplete or missing data that may disrupt model training.
An additional focus of data cleaning is mitigating biases within the dataset. Addressing biases is essential to ensuring the LLM produces fair and ethical predictions and reduces the risk of perpetuating harmful, discriminatory behavior.
Data Augmentation
Data augmentation techniques are essential for improving models' robustness and generalization capabilities. Methods such as paraphrasing, back-translation, and synthetic data generation are commonly employed to expand training datasets.
Paraphrasing, for instance, involves rewording sentences without altering their core meaning, while synonym replacement substitutes words with similar terms to create varied input patterns. Back-translation translates text to another language and back, introducing natural variations.
Open-source tools for data collection and preparation
- NLTK: A comprehensive library for natural language processing tasks, including tokenization, stemming, and lemmatization.
- Pandas: A data manipulation library for transformation tasks like normalization, encoding, and feature engineering.
- Apache NiFi: An open-source tool that helps automate data flow between systems for extracting and transforming data.
- Apache Spark: An open-source unified analytics system for large-scale data processing.
- Talend: An open-source data integration platform offering tools for data extraction, transformation, and loading (ETL).
Model Training or Fine-tuning
Once the data is prepared, the next step is either training an LLM from scratch or, more commonly, fine-tuning a pre-trained model for specific tasks. Training an LLM from scratch is computationally expensive and impractical for most applications.
Therefore, fine-tuning pre-trained models is the preferred approach to adapting general-purpose LLMs for specific use cases.
LLM Selection
Selecting the appropriate foundation LLM depends on the specific task and requirements to achieve optimal performance.
Factors to consider while selecting the LLM include:
- Model Size: The size of an LLM significantly impacts both its performance and resource requirements. Larger models generally perform better on complex tasks due to their capacity but demand more computational power and memory. Depending on the specific task and resource constraints, smaller models might be more efficient and cost-effective while providing sufficient performance.
- Architecture: Some architectures are better suited for text generation tasks (e.g., GPT), while others excel in understanding and classification (e.g., BERT). Understanding the strengths of each architecture helps in aligning them with the specific task requirements. For instance, GPT might be ideal for generating coherent responses in a chatbot, while BERT can be more effective for tasks like question answering and sentiment analysis.
- Pre-training Data: The diversity, quality, and diversity of the data used during the pre-training phase significantly affect its generalization capabilities. Models like GPT-4, trained on vast and varied datasets, can perform better in diverse domains. Evaluating the relevance of the pre-training data to the target task is important for selecting the best model.
Organizations can choose the LLM that best meets their project’s performance and resource requirements by considering model size, architecture, and pre-training data.
Fine-Tuning for Specific Tasks
Once the appropriate language model has been selected, the next step is fine-tuning it. Fine-tuning involves adapting the pre-trained LLM to a specific task, such as summarization, translation, or sentiment analysis.
Fine-tuning improves the model's ability to handle domain-specific understanding by training it on a smaller, curated dataset compared to the datasets used for pre-training.
The fine-tuning process is iterative and requires careful attention to several key areas:
- Hyperparameter Optimization: Tuning parameters like learning rate, batch size, and number of epochs is important to optimizing the model's performance on a given task. Additionally, LLM-specific parameters such as context window size, prompt length, temperature (which Controls the randomness of the model's output), and Top-k sampling have an important role in managing the model's ability to process longer inputs. Fine-tuning is a delicate process, where improper adjustments can result in overfitting or underperformance.
- Experimentation: Testing different model configurations, training strategies, and prompt designs helps identify the best-performing approach.
- Reproducibility: It’s important to document and version all training parameters, datasets, and code to ensure results can be replicated and validated.
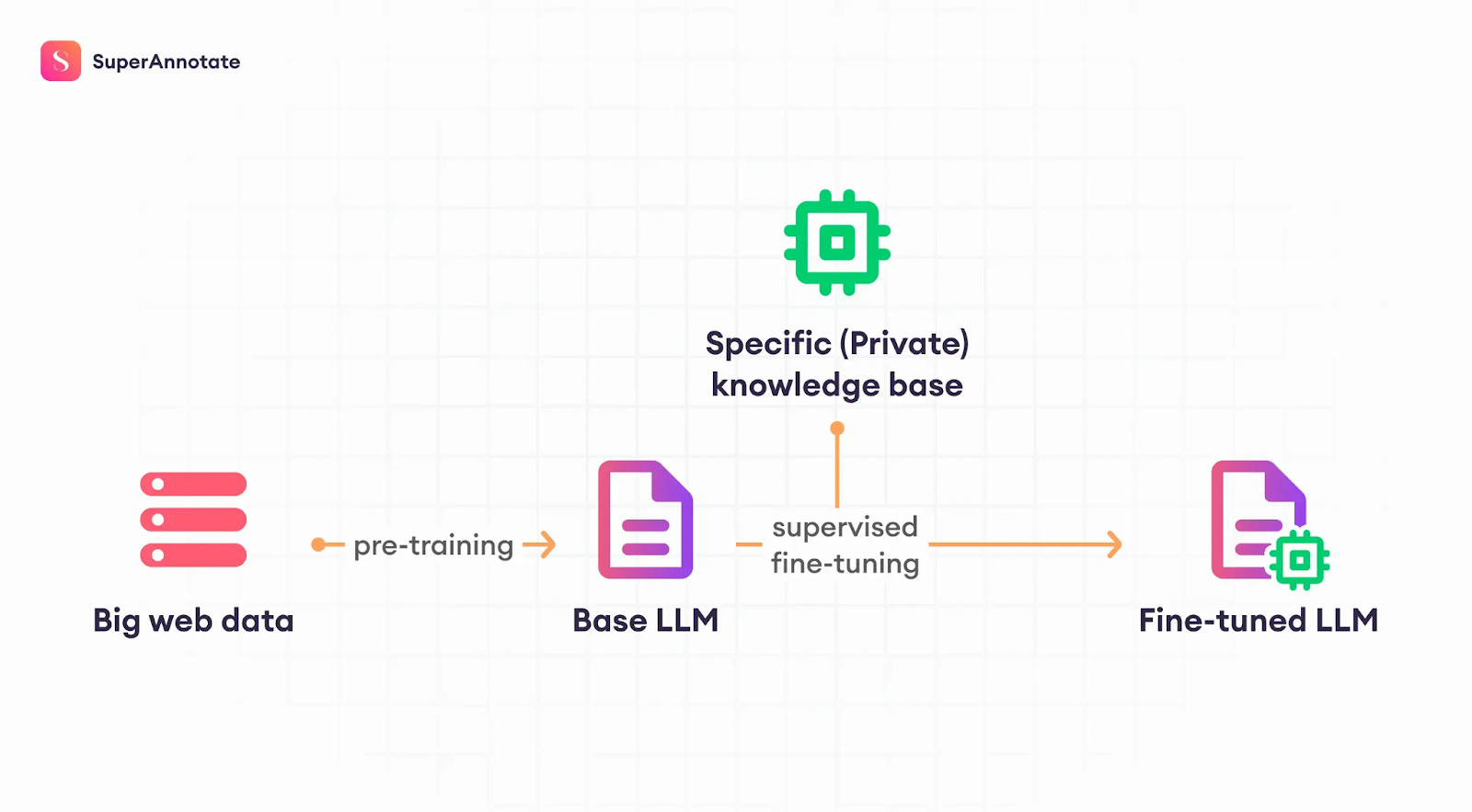
Fine-tuning Large Language Models | Source
Open-source tools for model training or fine-tuning
- Hugging Face Transformers: A comprehensive library for accessing and fine-tuning various LLMs.
- TensorFlow and PyTorch: Popular deep learning frameworks for building and training custom models.
Model Evaluation and Validation
After training or fine-tuning, a model must undergo thorough evaluation and validation to verify that it meets the desired performance criteria for the specific task and adheres to ethical guidelines. Evaluation metrics vary based on the task.
Task-specific Metrics
Evaluating LLMs depends heavily on the nature of the task they are designed to perform. For classification tasks, metrics accuracy, precision, recall, and F1-score are used. In generative tasks like translation or summarization, metrics such as BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation) are used.
Another important metric is perplexity, which measures the model's ability to predict the next word in a sequence. Lower perplexity scores show that the model better understands context and generates more coherent text.
Open-source Tools for Evaluation and Validation
- RAGAS: A framework for evaluating retrieval-augmented generation, specifically useful in LLM evaluations.
- Athina Evals: An evaluation framework designed for LLM-powered applications to assess metrics like relevance and faithfulness.
- Deepeval: An open-source for evaluating the performance of LLMs. It assesses their generated text for coherence, relevance, and factual accuracy.
For instance, if you’ve developed an LLM application (such as the RAG app) and want to evaluate its retrieval and response quality, Athina EvalI provides a method for assessment. Here's how to use it to evaluate these aspects:
Example Code:
import os
from athina.evals import DoesResponseAnswerQuery, ContextContainsEnoughInformation, Faithfulness
from athina.loaders import Loader
from athina.keys import AthinaApiKey, OpenAiApiKey
from athina.runner.run import EvalRunner
from athina.datasets import yc_query_mini
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
# Configure an API key.
OpenAiApiKey.set_key(os.getenv('OPENAI_API_KEY'))
# Load the dataset
dataset = [
{
"query": "query_string",
"context": ["chunk_1", "chunk_2"],
"response": "llm_generated_response_string",
"expected_response": "ground truth (optional)",
},
{ ... },
{ ... },
{ ... },
]
# Evaluate a dataset across a suite of eval criteria
EvalRunner.run_suite(
evals=[
RagasAnswerCorrectness(),
RagasContextPrecision(),
RagasContextRelevancy(),
RagasContextRecall(),
RagasFaithfulness(),
ResponseFaithfulness(),
Groundedness(),
ContextSufficiency(),
],
data=dataset,
max_parallel_evals=10
)Next, we will see how to deploy your LLMOps project.


