LLMOps Part 3: Deployment

After completing the development and validation phase, model deployment is the next important step in the LLMOps workflow. Successful deployment requires careful consideration of efficiency, scalability, and the specific needs of the deployment environment.
Quantization: Optimization Technique for Efficient Deployment of LLMs
Quantization is a technique used to reduce LLMs' size and computational cost for resource-constrained environments without impacting their performance. This process is important for edge-device applications, where computational resources are limited.
Quantization includes the following techniques:
- Lower Precision Representation: Quantization reduces the precision of the model's parameters, commonly converting from 32-bit floating-point numbers to lower-precision formats like 8-bit integers. This reduction in precision can lead to faster inference times and lower memory usage. As a result, models can be deployed more efficiently on high-throughput applications.
- Weight Pruning: Weight pruning complements quantization by removing less important connections or weights from the model. Eliminating these non-important components reduces the model’s size and complexity and does not significantly affect accuracy drop.
- Knowledge Distillation (KD): Knowledge distillation is another effective approach to model optimization, in which a smaller "student" model is trained to mimic the behavior of a larger "teacher" LLM. The student model, being more compact and efficient, is more suitable for real-time deployment on edge devices.
Deployment Strategies
Deploying LLMs can differ depending on operational needs and constraints. The common strategies for deploying the LLMs include cloud-based, edge, and on-premise deployments.
- Cloud-Based Deployment: Cloud-based deployment is a popular strategy for hosting LLMs and benefits scalability, flexibility, and ease of management. Major cloud providers like AWS SageMaker, Google Cloud AI, and Microsoft Azure help organizations leverage managed services and dynamic scaling based on powerful hardware (such as GPUs and TPUs).
- Edge Deployment: Edge deployment involves deploying LLMs on devices closer to the data source, such as smartphones, IoT devices, or embedded systems. This strategy is essential when low-latency responses or offline access are needed.
- On-Premise Deployment: On-premise deployment gives control over the model and infrastructure and benefits for organizations with strict data security or regulatory requirements. This strategy hosts LLMs on local servers or data centers, giving businesses greater control over their data and the computing environment.
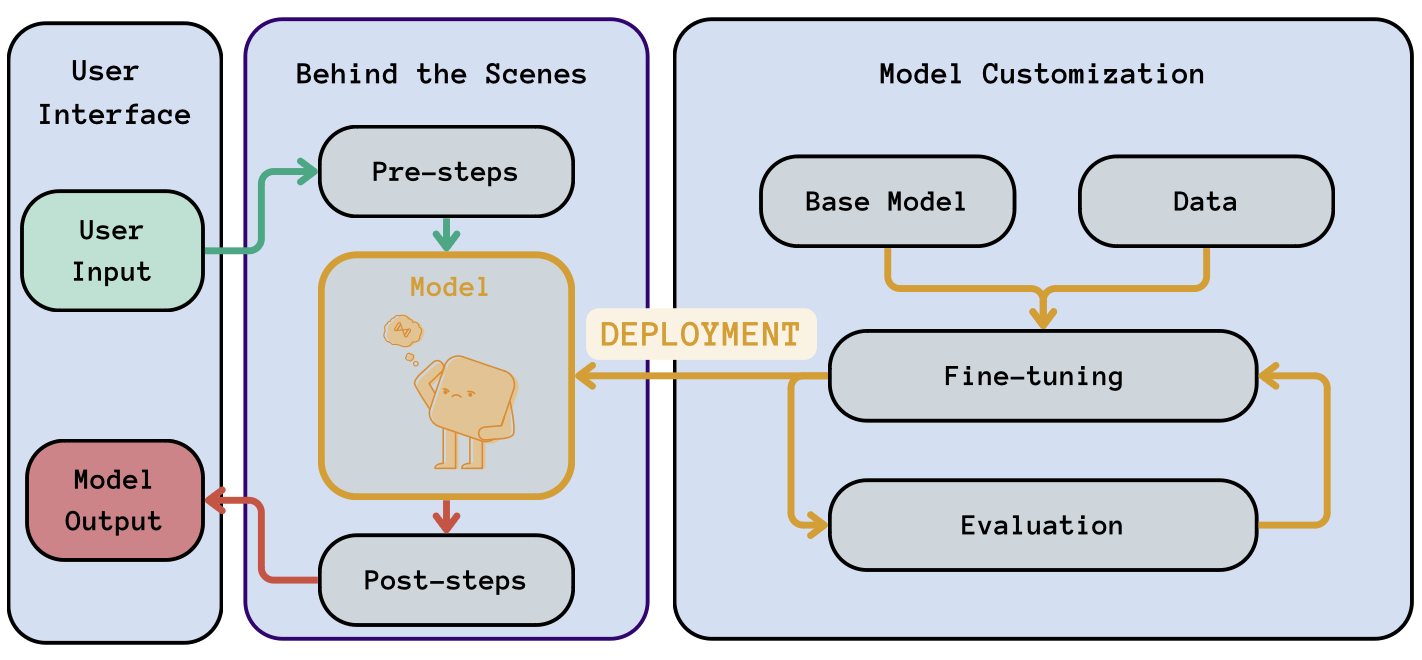
Deployment Generic Workflow | Source
Open-source Tools for Model Deployment
- Docker: A containerization platform that ensures consistency and isolation for deployed LLMs by packaging them with their dependencies, libraries, and runtime environment.
- Flask and FastAPI: Lightweight frameworks for building RESTful APIs to serve model predictions.
- Hugging Face Inference Endpoints: Platform provided by Hugging Face for easy deployment and scaling of LLMs with features like serverless inference and optimized infrastructure.
- TensorFlow Serving: A flexible, high-performance system for serving machine learning models in production environments.
- TorchServe: A PyTorch model serving library that simplifies the deployment of PyTorch models, including LLMs.
- BentoML: An open-source framework for developing, deploying, and managing machine learning models.
Automating CI/CD for LLM Workflows
CI/CD pipelines are important for automating updates, testing, and deployment in LLM workflows. They streamline the process from model development to production, ensuring faster iterations and consistent performance.
Pipeline Configuration
CI/CD pipelines reduce manual intervention and ensure that LLMs are consistently optimized based on new data or requirements by automating key stages in the LLM workflow.
CI/CD pipeline for LLMs includes the following automated stages:
- Data Ingestion and Validation: Automate data collection, validate its quality, and preprocess it for model training or fine-tuning.
- Model Training and Fine-tuning: Automate the process of training or fine-tuning the LLM, including selecting the appropriate base model, configuring hyperparameters, and executing the training process on scalable infrastructure.
- Model Evaluation and Testing: Automate the evaluation and testing of the trained or fine-tuned model using relevant metrics and a comprehensive suite of tests. Testing includes Unit tests, integration tests, and performance tests.
- Model Deployment: Automate the deployment of the trained, fine-tuned, and validated LLM to the target environment (cloud, edge, or on-premise).
- Monitoring and Logging: Automated monitoring and logging to track the LLM's performance, resource usage, and potential issues.
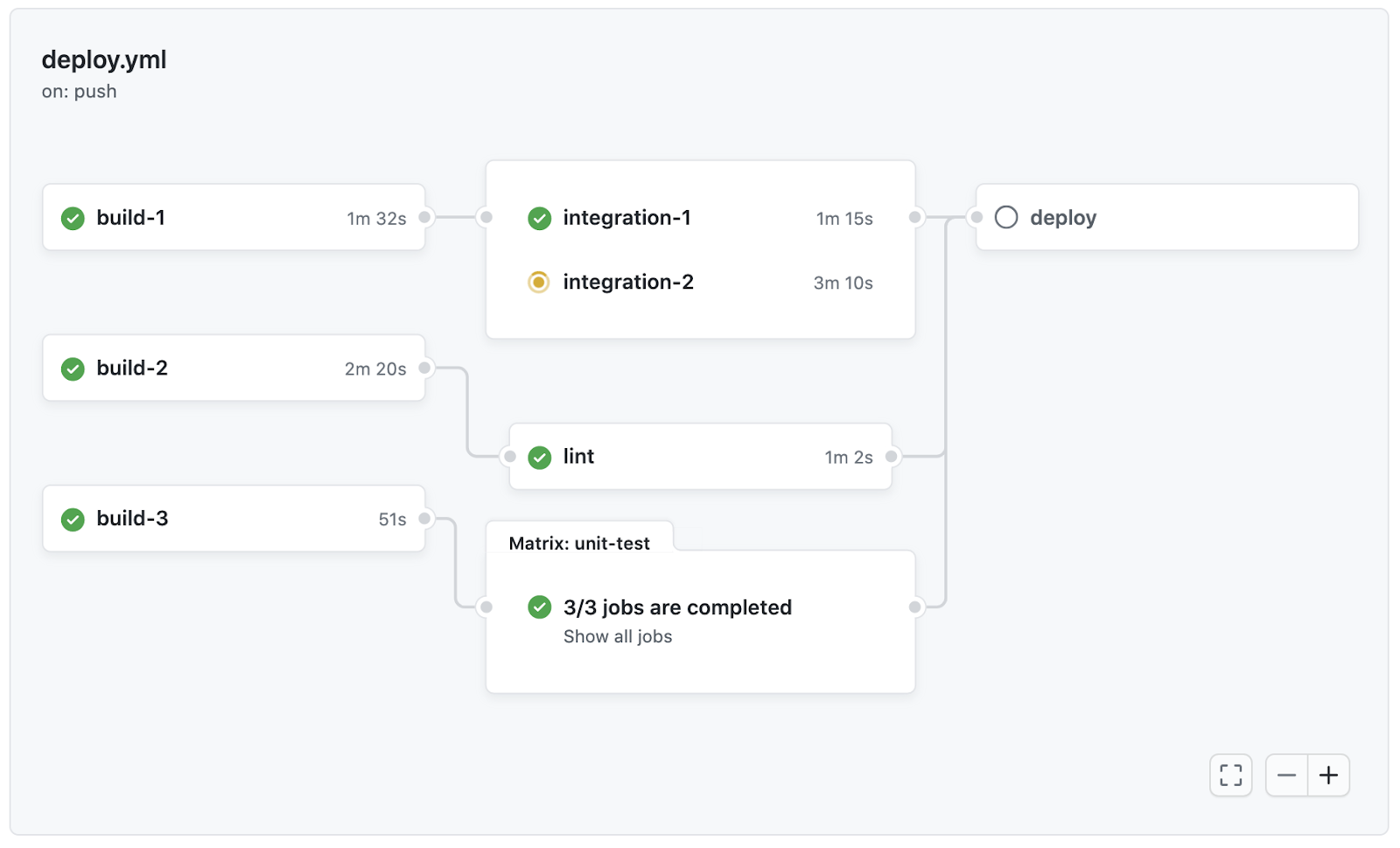
A Sample CI/CD Pipeline Visualization| Source
Continuous Deployment
Once models pass testing, they are deployed automatically to production environments. Continuous deployment guarantees that LLMs receive timely updates, minimizing risks like performance degradation or data drift.
- Automated Deployment Pipelines: Pipelines automatically deploy models to environments like staging and production upon successful testing.
- Version Control and Rollbacks: Track model versions and configurations, allowing for quick rollbacks if issues arise.
- Blue/Green Deployments: Deploy the new version alongside the existing version, allowing seamless transitions with minimal downtime.
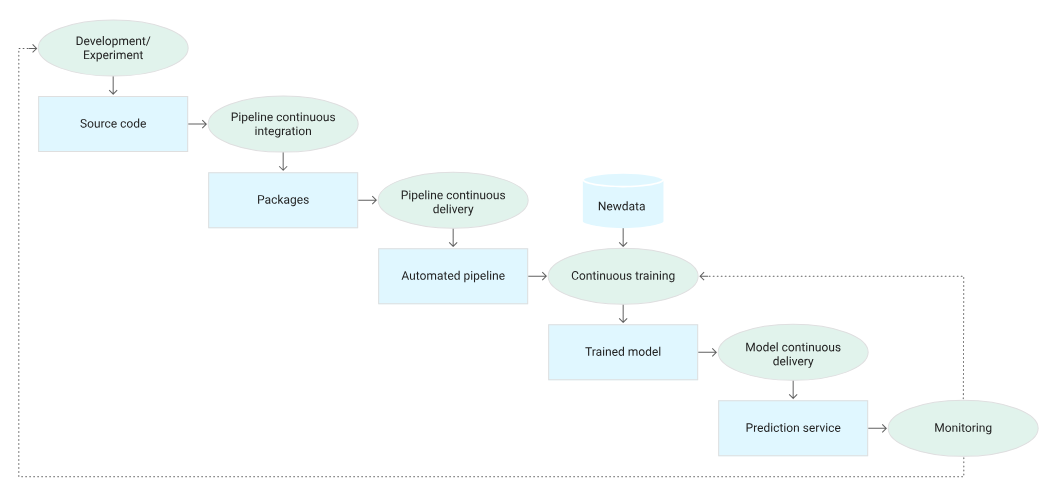
CI/CD Automated ML Pipeline | Source
Open-source Tools for CI/CD
CI/CD pipelines for LLM can be implemented using tools such as:
- DVC (Data Version Control): DVC is an open-source tool that extends Git's capabilities to manage large datasets for LLM.
- MLflow: Open-source platform for managing the LLM lifecycle, including experimentation, logging, tracking, and deployment.
- Jenkins: This open-source automation server is widely used for setting up customizable CI/CD pipelines. It is highly flexible and scalable and integrates well with other tools for building, testing, and deploying models.
- GitHub Actions: GitHub Actions allows developers to automate their workflows directly from their GitHub repositories. It's used for automating model training, fine-tuning, deployment, and retraining or retuning based on code changes.
- GitLab CI/CD: GitLab integrated CI/CD pipelines into its platform, automating code changes and building LLMs.
Model Monitoring
Model monitoring is the process of evaluating the effectiveness and efficiency of an LLM in production. Continuous monitoring ensures the model maintains its original performance, behaves as expected, and aligns with ethical guidelines.
This includes tracking key metrics, analyzing model behavior, detecting drifts in data or model output, and setting up automated alerts to address issues in real time.
Over time, an LLM's performance may decline due to various factors, such as shifts in data distribution, evolving user needs, or the emergence of new, unaccounted-for information.
Teams can quickly detect these changes and take appropriate action, such as retraining or fine-tuning, to maintain accuracy and relevance by continuously monitoring the model.
- Performance Metrics Tracking: The system should track the model’s performance metrics (e.g., accuracy, precision, recall) over time. A model that performs well on initial deployment may degrade as the data changes.
- Model Behavior Analysis: Monitoring for bias and fairness is essential to ensuring ethical outputs. Techniques like explainable AI (XAI) provide transparency into the model's reasoning. Detecting data drift or changes in user behavior helps address unexpected outcomes proactively.
- Logging and Alerts: Monitoring tools log all incoming data, performance degradation, anomalies, or potential issues. Alerts are triggered when performance degrades or drift is detected to notify the engineering teams.
Open-source Tools for Continuous Monitoring
- Evidently AI: Monitors data drift and model performance.
- Prometheus: A tool for collecting and querying time-series data, tracking performance metrics, and triggering alerts based on predefined thresholds.
- Grafana: An open-source tool that works well with Prometheus to visualize model metrics over time.
- Langfuse: Monitor, debug, and analyze LLMs in production.
- Athina IDE: Specifically designed for logging and monitoring LLM applications.
Athina IDE offers a suite of features designed to streamline the monitoring and evaluation of LLMs. It automatically visualizes usage metrics, including response time, cost, token usage, and feedback, clearly and concisely.
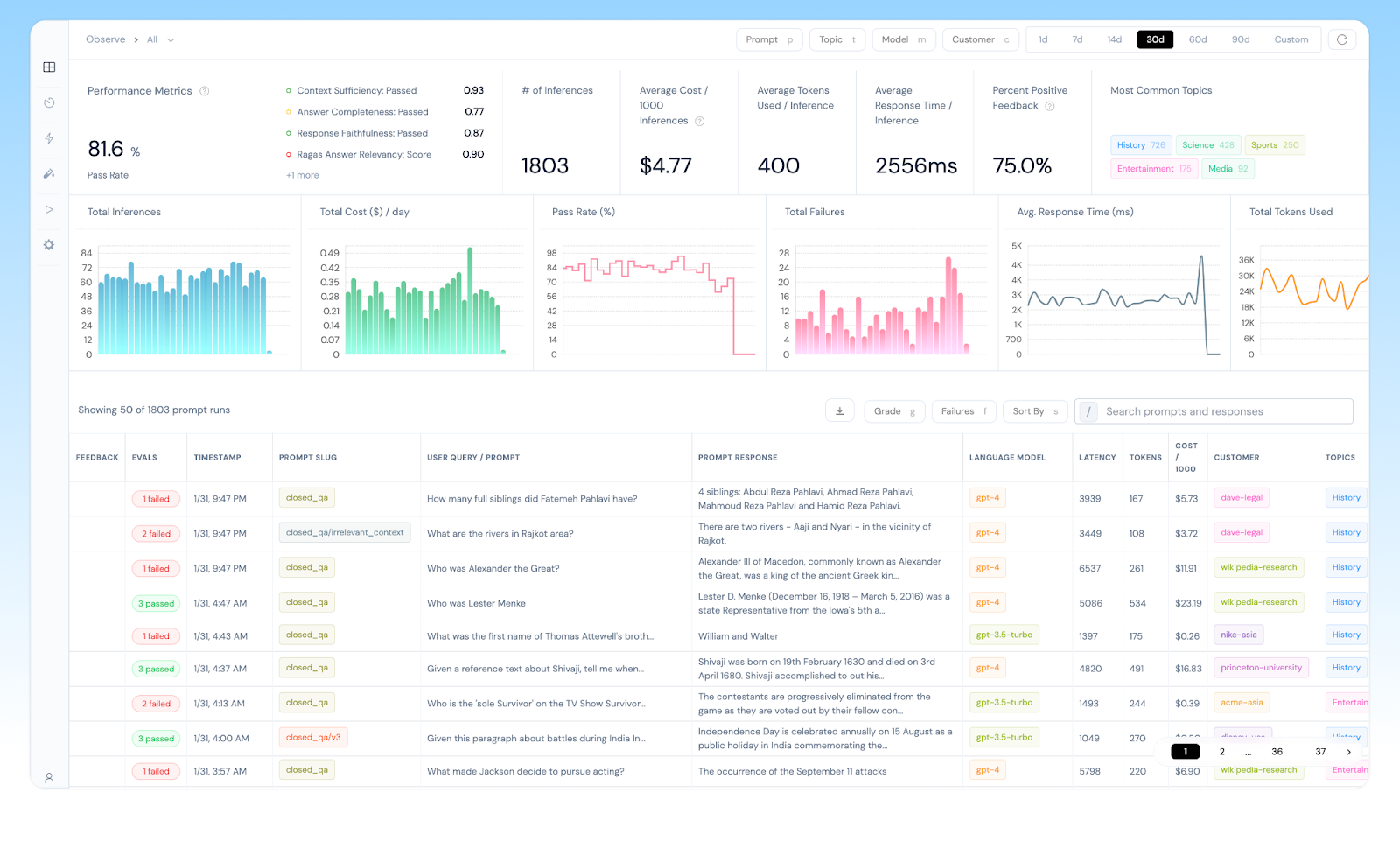
Athina IDE Monitor | Source
LLM Governance
LLM governance provides the framework for responsible development, deployment, and use of LLMs. It includes policies, procedures, and practices that ensure LLMs are used ethically, transparently, and in compliance with regulations.
Data Governance
Data governance plays a foundational role in LLM governance. It ensures data quality, integrity, and ethical use throughout the LLM lifecycle.
Key aspects of data governance for LLMs include:
- Data Quality: Establish processes to ensure training data's accuracy, completeness, and consistency. This includes addressing issues like bias, noise, and representation imbalances.
- Data Privacy: Implement measures to protect the privacy of individuals whose data is used to train or interact with the LLM. This includes complying with data protection regulations like the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA).
- Data Security: Secure data against unauthorized access, use, or disclosure. This involves implementing security measures throughout the data lifecycle, from collection and storage to processing and disposal.
- Data Provenance: Maintain a clear record of data's origin, processing, and usage. This helps ensure accountability and transparency in how data is used to train and operate the LLM.
- Ethical Considerations: Address ethical considerations related to data usage, such as avoiding the use of copyrighted or sensitive data, mitigating biases, and promoting fairness.
Regulatory Principles
The principles include explainability (LLMs should provide reasoning for their results), privacy (organizations should not have to share sensitive data), and responsibility (ensuring safe integration of LLMs into regulated industries).
- Transparency: Provide clear information about the LLM's work, limitations, and potential biases.
- Accountability: Establish clear lines of responsibility for the LLM's outputs and actions. This ensures that someone is accountable for any unintended consequences or harms.
- Human Oversight: Maintain human oversight in critical decision-making processes involving LLMs. This ensures that humans remain in control and can intervene to prevent harm or correct errors.
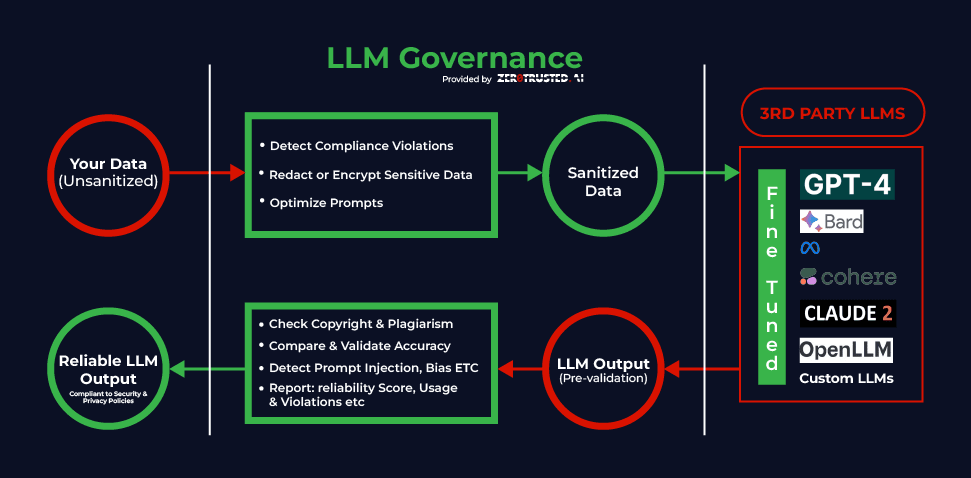
LLM Governance | Source
Additional Resources
For more information about how to get started with Athina AI and LLMOps, see the following guides and articles:
- Evaluation Best Practices
- Running evals as real-time guardrails
- https://arxiv.org/pdf/2404.00903
- https://arxiv.org/abs/2408.13467
- https://www.analyticsvidhya.com/blog/2023/09/llmops-for-machine-learning-engineering/
- https://towardsdatascience.com/llm-monitoring-and-observability-c28121e75c2f
- https://www.ibm.com/topics/llmops
- https://cloud.google.com/discover/what-is-llmops?hl=en



{kind=link}