Implementing Self-Reflective RAG using LangGraph and FAISS

As we build more complex AI applications day by day, there is a need to implement advanced RAG techniques to get better responses from LLMs.
We all know RAG is the fundamental piece in building LLM systems. It enables LLMs to generate contextually relevant responses by using external knowledge sources.
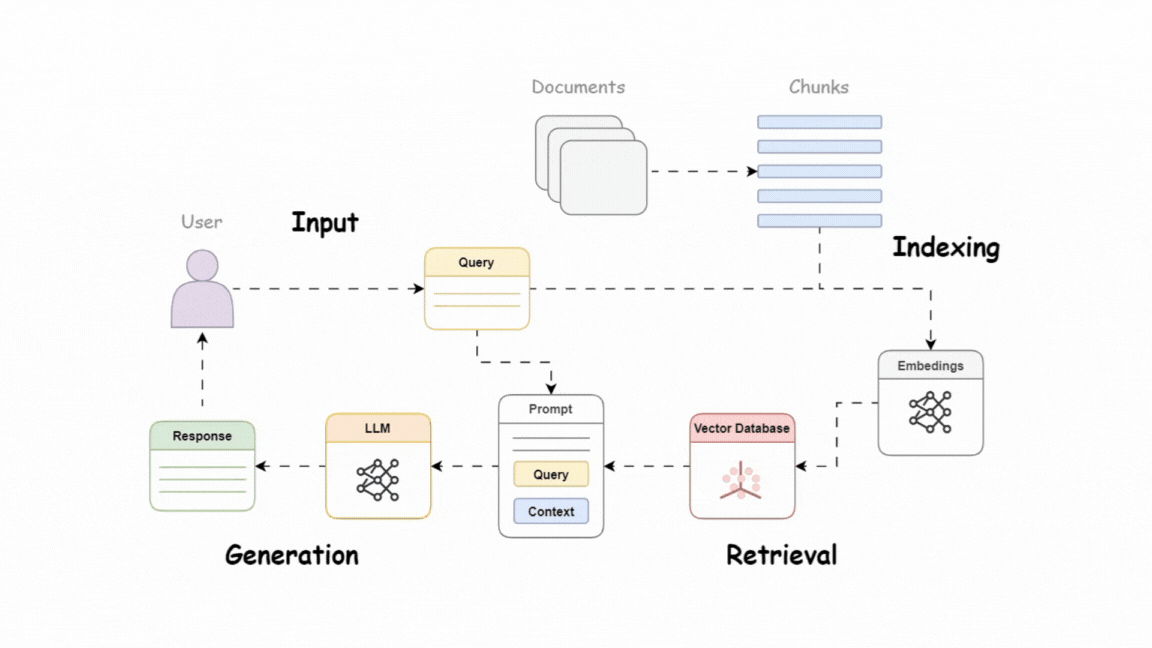
As a quick recap here’s how the RAG pipeline works:
- Takes user query as an input
- Generates embeddings of the query to retrieve documents relevant to the query from the vector store.
- Using the retrieved document to construct prompt and passing it to an LLM
- Response generation by the LLMs
However, basic RAG has a few shortcomings that makes it challenging to use it for advanced applications:
- Straight sequential process - RAG is designed to retrieve documents for every query, even when it is not necessary. This can lead to stuffing unnecessary information to LLM which reduces the output quality.
- Fetching non-relevant documents - A lot of times, not all retrieved documents are relevant to the query. Providing LLM with such irrelevant documents reduces the accuracy of the generated responses
To overcome these challenges, researchers have come up with a technique called Self-reflective RAG. Here’s the research paper: Arxiv Link
RAG vs Self RAG
Standard RAG retrieves information a fixed number of times, while Self-RAG dynamically decides when and how often to retrieve, making it more adaptable for diverse queries.
Additionally, Self-RAG evaluates the relevance of retrieved passages and generated outputs through reflection, ensuring more accurate and contextually aligned responses.
Comparison: RAG vs Self RAG
| Feature | Standard RAG | Self-RAG |
|---|---|---|
| Retrieval Strategy | Fixed number of retrievals | Adaptive retrieval (can retrieve multiple times or skip retrieval) |
| Task Adaptability | Limited to predefined steps | Adjusts retrieval based on input complexity |
| Relevance Assessment | No assessment of passage relevance | Critiques retrieved passages and generated responses via reflection tokens |
| Decoding Constraints | No constraints | Uses hard or soft constraints for better generation control |
| Suitability | Works well for static queries | Ideal for instruction-following and dynamic tasks |
Let’s understand Self RAG and its components in detail:
Self-Reflective RAG
Self-reflection is a smarter approach to RAG. Instead of retrieving documents for every query and blindly using them for response generation, Self-RAG takes logical reasoning throughout the entire workflow.
Self-RAG framework uses an arbitrary LLM to adaptively retrieve documents on demand. It instructs the LLM to decide whether it should retrieve information for a query or not, and if yes, then how to critically review the retrieved information.
Here’s how it works:
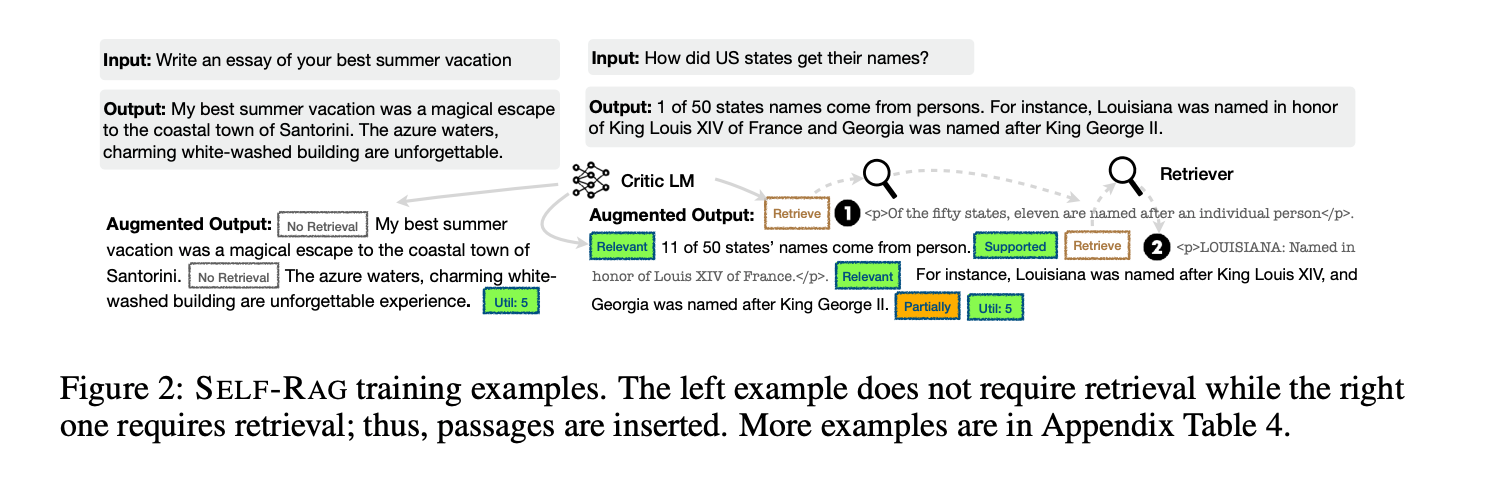
1. Reflection Tokens
Self-RAG uses special tokens called “reflection tokens”. The framework trains a model to generate these tokens that guides the model to take actions during the entire workflow. There are 4 types of reflection tokens:
Retrieve: The model analyzes the query to determine if it can answer the query with its existing knowledge or does it needs to retrieve additional information. Once generated, this token indicates that the model needs to retrieve external information.ISREL(Is Relevant): This token helps the model to identify whether the retrieved information is relevant or not. After retrieval, the model uses this token to filter out irrelevant information that can pollute the response.ISSUP(Is Supported): This token is generated if the model’s output is supported by the retrieved information.ISUSE(Is Useful): The model generates this token to rate the relevance of output to the user’s query. This is the final quality check that ensures the generated response is not only grounded but helpful to the user as well.
By using these tokens, Self-RAG makes the entire RAG logical and helps to determine how a model arrived to a conclusion.

2. Retrieval
As discussed earlier, basic RAG follows a standard process that retrieves information for every query it gets.
Self-RAG only does the retrieval when the model finds it necessary. The model first attempts to answer the query using its inherent knowledge.
If it determines that external information is required, it uses the Retrieve token to fetch the documents from the external knowledge base.
Unlike basic RAG, Self-RAG does not use these retrieved documents directly to generate responses. It follows a scoring mechanism to evaluate the relevance of the retrieved data. Let’s see how it works
3. Critiquing the Retrieval
In this step, the model uses the three tokens we’ve discussed earlier - ISREL, ISSUP, ISUSE to assess the relevance of the retrieved documents.
- After retrieval, the model assesses the relevance of fetched documents using the
ISRELtoken and determines if it is relevant or irrelevant. The output isrelevantorirrelevant - It then uses
ISSUPtoken to identify whether the LLM generation from each document is supported by the document or not. This token decides if the output isfully supported,partially supportedornot supported - At last, the model uses the
ISUSEtoken to decide how useful the generated response is to the input on a scale of 1 to 5.
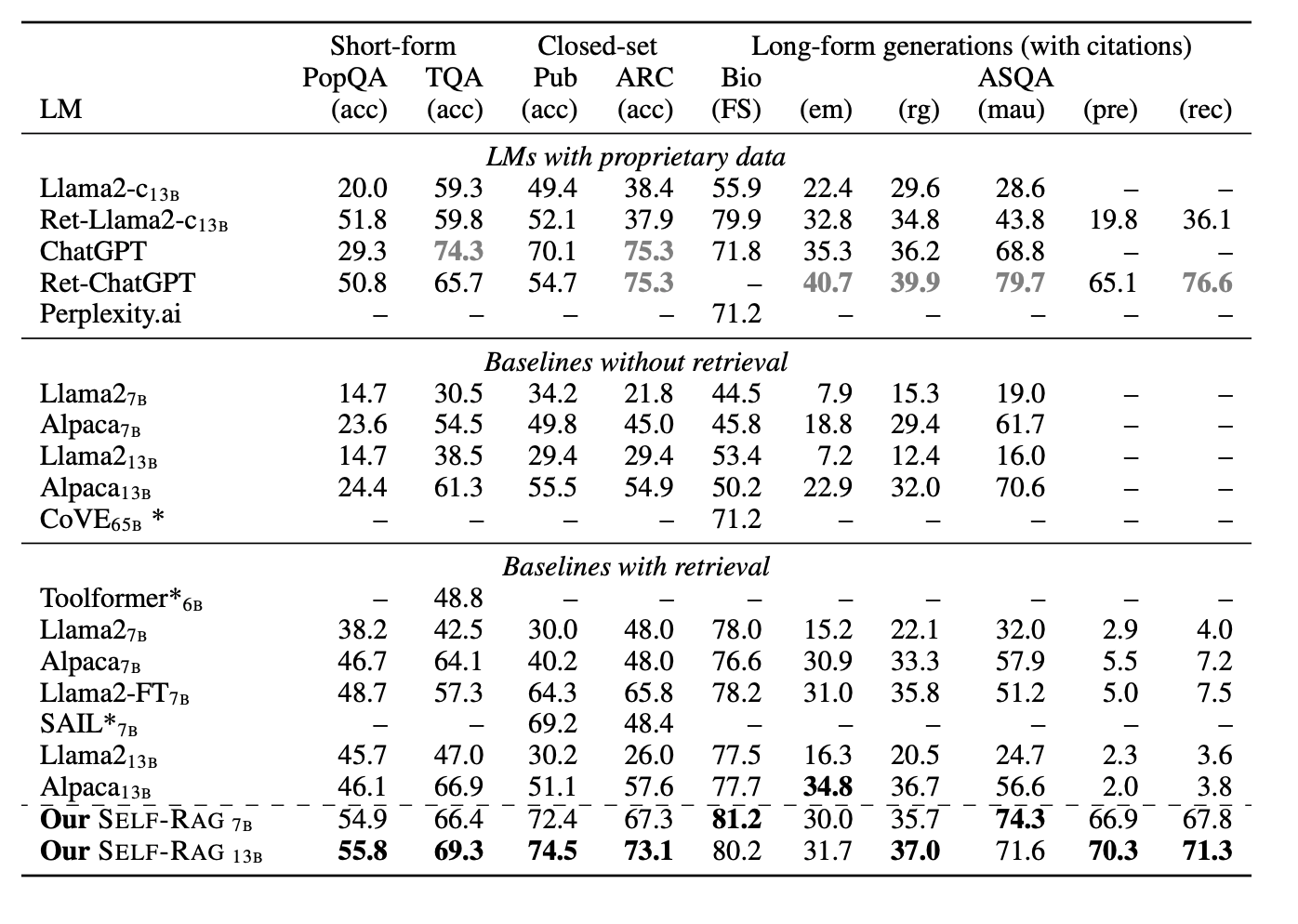
Self-RAG Performance
Researchers tested the performance of Self-RAG by performing experiments on six tasks and comparing it with various open-source and proprietary models. They used, Llama2 7B and 13B as generator models while Llama2 7B as a critique model.
The Bold number in the following table indicates the best performance among non-proprietary models while Gray-colored text indicates the best proprietary model that outperforms all non-proprietary models.
Implementation
Here's a step-by-step guide about how we implemented Self RAG using LangGraph. You can access the entire notebook on our GitHub.
1. Installing Libraries and Setting Up Environment
We'll start with installing the necessary libraries and configuring the environment variables:
! pip install --q athina faiss-gpu langgraphimport os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
os.environ['ATHINA_API_KEY'] = userdata.get('ATHINA_API_KEY')2. Loading Embedding model, Documents and Preparing Embeddings
We'll be using the OpenAIEmbeddings model for generating the vectors. Next, load your documents (CSV file) and prepare them for embedding generation. Split the document using the standard Recursive text splitter
# load embedding model
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()# load data
from langchain.document_loaders import CSVLoader
loader = CSVLoader("./context.csv")
documents = loader.load()# split documents
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
documents = text_splitter.split_documents(documents)3. Creating a Vector Store with FAISS
Now, create a vector store to store document embeddings for efficient similarity search.
# create vectorstore
from langchain.vectorstores import FAISS
vectorstore = FAISS.from_documents(documents, embeddings)4. Setting Up the Retrievers
Define retriever from the vector store
# create retriever
retriever = vectorstore.as_retriever()5. Setting up a Grader/Evaluator for Documents
Here we'll define the grader function that will grade the retrieved documents as relevant or irrelevant. The output for the grader would be a boolean - yes/no.
Note: LangGraph takes a different approach in grading the retrieved documents as compared to the paper
Here's how the approach looks like with LangGraph:
- Evaluate Retrieved Documents – We check each retrieved document for relevance.
- Proceed if Relevant – If at least one document is useful, we generate a response.
- Refine and Retry if Needed – If none are relevant, we improve the query and search again.
# create grader for doc retriever
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# define a data class
class GradeDocuments(BaseModel):
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Prompt for the grader
system = """You are a grader assessing relevance of a retrieved document to a user question. \n
If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
retrieval_grader = grade_prompt | structured_llm_grader6. Testing the Grader
# testing grader
question = "what are points on a mortgage"
docs = retriever.invoke(question)
print(retrieval_grader.invoke({"question": question, "document": docs}))binary_score= 'yes'Score 'Yes' means that at least one document fetched by the retriever is relevant.
7. Set up a RAG Chain
In this step, we'll set up a RAG chain that takes user's query and a set of retrieved documents to generate an answer. We'll also define the prompt template.
At the end we'll use an output parser to format the generated output so that it is easier to read.
Note: LangGraph takes a different approach in grading the retrieved documents as compared to the paper
Here's how the approach looks like with LangGraph:
- Single vs. Multiple Generations: Instead of generating a response for each chunk separately (as done in the paper), we generate a single response using all relevant documents.
- Grading for Accuracy: The generated response is graded in two ways:
- Against the documents – To prevent hallucinations.
- Against the expected answer – To ensure correctness.
- Efficiency Benefits: This approach reduces the number of LLM calls, improves latency, and allows more context to be included in the response.
- Flexible Approach: If more control is needed, we can still generate responses per chunk and grade them individually.
# create document chain
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain.prompts import ChatPromptTemplate
template = """"
You are a helpful assistant that answers questions based on the following context
Context: {context}
Question: {question}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(temperature=0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = prompt | llm | StrOutputParser()# response
generation = rag_chain.invoke({"context": docs, "question": question})
generationOutput:
"Points on a mortgage, also known as discount points, mortgage points, or simply points, are a form of pre-paid interest that can be paid by a borrower to a lender when arranging a mortgage. One point is equal to one percent of the loan amount. By paying points, a borrower can effectively reduce the interest rate on the loan, resulting in a lower monthly payment. Points can also be used to qualify for a loan based on monthly income versus the monthly loan payment. It's important to note that points are different from origination fees, mortgage arrangement fees, or broker fees."
8. Hallucination Grader
The hallucination grader checks whether the response generated by the LLM is supported by the
# create grader for hallucination
# define a data class
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: str = Field(
description="Answer is grounded in the facts, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)
# prompt for the grader
system = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts."""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
]
)
hallucination_grader = hallucination_prompt | structured_llm_grader
hallucination_grader.invoke({"documents": docs, "generation": generation})
GradeHallucinations(binary_score='yes')
9. Answer Grader
# create grader for answer
# define a data class
class GradeAnswer(BaseModel):
"""Binary score to assess answer addresses question."""
binary_score: str = Field(
description="Answer addresses the question, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeAnswer)
# prompt for the grader
system = """You are a grader assessing whether an answer addresses / resolves a question \n
Give a binary score 'yes' or 'no'. Yes' means that the answer resolves the question."""
answer_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "User question: \n\n {question} \n\n LLM generation: {generation}"),
]
)
answer_grader = answer_prompt | structured_llm_grader
answer_grader.invoke({"question": question, "generation": generation})
GradeAnswer(binary_score='yes')8. Setting up the LangGraph Workflow
To build the CRAG workflow with LangGraph, follow these three main steps:
- Define the graph state
- Define function nodes
- Connect all function nodes
Define Graph State
# define a data class for state
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
question: str
generation: str
documents: List[str]# # define graph steps
# from langchain.schema import Document
# all nodes
def retrieve(state):
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.get_relevant_documents(question)
return {"documents": documents, "question": question}
def generate(state):
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}
# edges
def decide_to_generate(state):
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION---"
)
return "no_relevant_documents"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.binary_score
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"Build Graph
# Build graph
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("generate", generate)
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"generate": "generate",
"no_relevant_documents": END,
},
)
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
},
)
# Compile
app = workflow.compile()
Example 1
Here's an example of a case when relevant documents (or atleast one relevant document) are retrieved by the retriever
# Final generation example 1 (relevant documents)
from pprint import pprint
inputs = {"question": "what are points on a mortgage"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Node '{key}':")
pprint("\n---\n")
if "generation" in value:
pprint(value["generation"])
else:
pprint("No relevant documents found or no generation produced.")Since we have a relevant document, the workflow moves forward with response generation step.
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'grade_documents':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
('Points on a mortgage, also known as discount points, are a form of pre-paid '
'interest that borrowers can pay to a lender when arranging a mortgage in the '
'United States. One point equals one percent of the loan amount. By paying '
'points, a borrower can reduce the interest rate on the loan, resulting in a '
'lower monthly payment. Points can also be used to qualify for a loan based '
"on monthly income versus the monthly loan payment. It's important to note "
'that points are different from origination fees, mortgage arrangement fees, '
'or broker fees.')Example 2
This is an example when no relevant documents are retrieved by the retriever
# example 2 (no relevant documents)
from pprint import pprint
inputs = {"question": "Explain how the different types of agent memory work?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Node '{key}':")
pprint("\n---\n")
if "generation" in value:
pprint(value["generation"])
else:
pprint("No relevant documents found or no generation produced.")s
It generates an output– 'No relevant documents found'
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION---
"Node 'grade_documents':"
'\n---\n'
'No relevant documents found or no generation produced.'s
9. Preparing Data for Evaluation
# Create a dataframe to store the question, context, and response
inputs = {"question": "what are points on a mortgage"}
outputs = []
for output in app.stream(inputs):
for key, value in output.items():
if key == "generate": # Assuming 'generate' node produces the final output
question = value["question"]
documents = value["documents"]
generation = value["generation"]
# Combine document contents into a single string
context = "\n".join(doc.page_content for doc in documents)
# Append the result
outputs.append({
"query": question,
"context": context,
"response": generation,
})---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---Here we'll use Pandas library to visusalize our data in a data frame.
# Convert to DataFrame
import pandas as pd
df = pd.DataFrame(outputs)df
# Convert to dictionary
df_dict = df.to_dict(orient='records')
# Convert context to list
for record in df_dict:
if not isinstance(record.get('context'), list):
if record.get('context') is None:
record['context'] = []
else:
record['context'] = [record['context']]
10. Evaluation using Athina AI
Athina AI is an LLM engineering platform that you can use to build, evalaute and monitor your LLM application. Athina supports leading open-source eval libraries such as— Protect AI, RAGAS, Guardrails, Open AI evals along with their own suite of evals
For our case we'll use the Does Response Answer Query eval to check if the generated response answers the query or not. You can learn more about this using this documentation.
# set api keys for Athina evals
from athina.keys import AthinaApiKey, OpenAiApiKey
OpenAiApiKey.set_key(os.getenv('OPENAI_API_KEY'))
AthinaApiKey.set_key(os.getenv('ATHINA_API_KEY'))# load dataset
from athina.loaders import Loader
dataset = Loader().load_dict(df_dict)# evaluate
from athina.evals import DoesResponseAnswerQuery
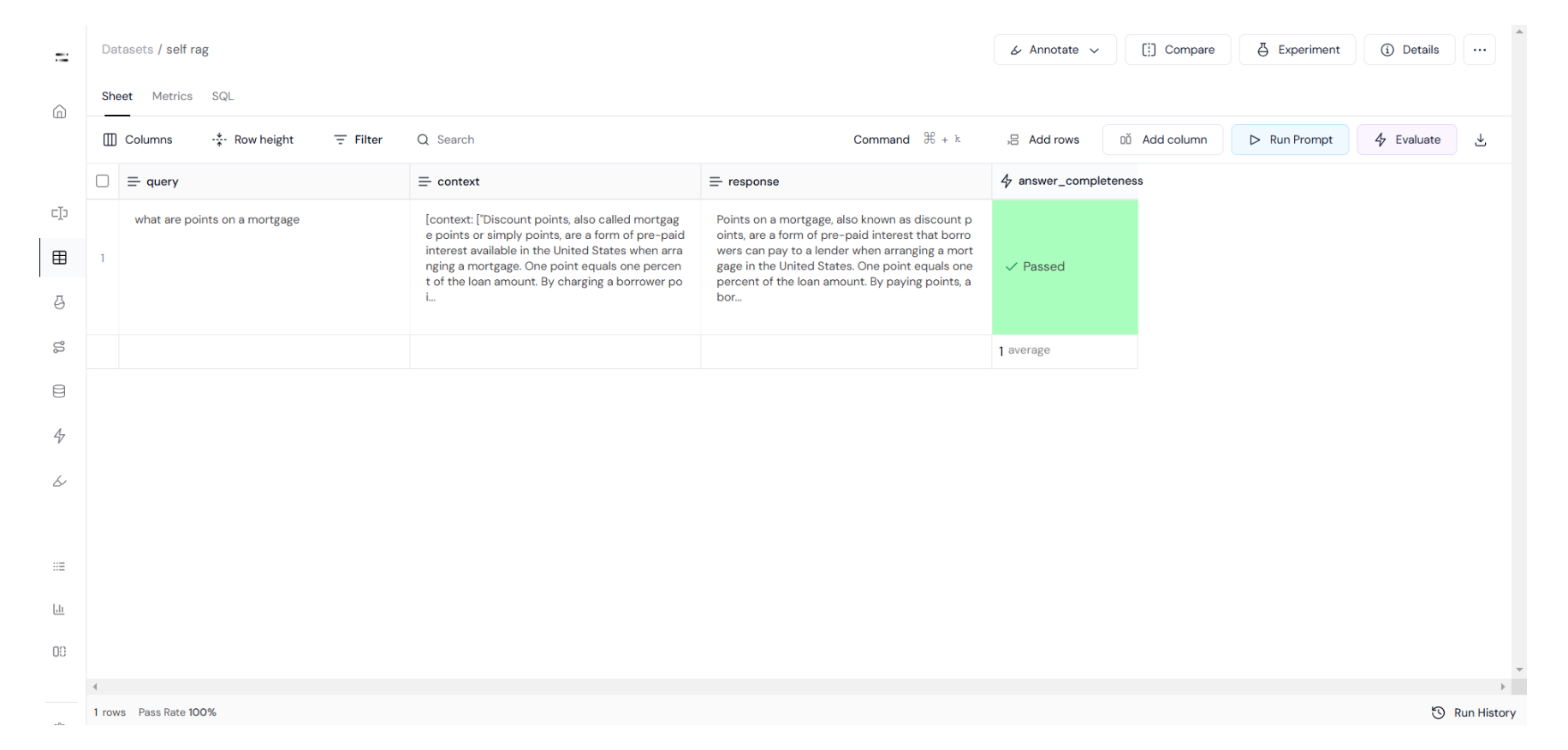
DoesResponseAnswerQuery(model="gpt-4o").run_batch(data=dataset).to_df()You can check the response on the UI like this:
Conclusion
Self-reflection is a powerful technique to improve retrieval quality and LLM responses in your AI applications.
If you're facing issues with your retrieval or LLM responses, there are other methods worth exploring—one of them is Corrective RAG (cRAG).
We’ve put together a step-by-step guide to help you implement cRAG. You can also check out our cRAG notebook on GitHub.


