RAG in Production: Best Practices

Retrieval Augmented Generation (RAG) systems are the backbone of an AI pipeline as they augment LLMs with external knowledge.
This ensures that AI responses are both precise and contextually relevant by grounding them in factual data.
This guide provides actionable insights for AI development teams, helping you build robust, scalable, and effective RAG systems.
By the end of this guide, you will learn how to:
- Optimize data ingestion and preprocessing
- Implement effective retrieval strategies
- Overcome common challenges in RAG deployment
- Deploy and monitor RAG systems effectively
Core Components of a RAG System
A modern Retrieval-Augmented Generation (RAG) system consists of three main pipelines:
- Indexing Pipeline: Ingests and preprocesses data, creates vector embeddings, and stores them in a fast vector database for easy retrieval.
- Retrieval Pipeline: Fetches relevant information from the indexed knowledge base using combined retrieval strategies and re-ranking techniques.
- Generation Pipeline: Combines retrieved data with user queries to produce clear, accurate, and contextually appropriate responses.
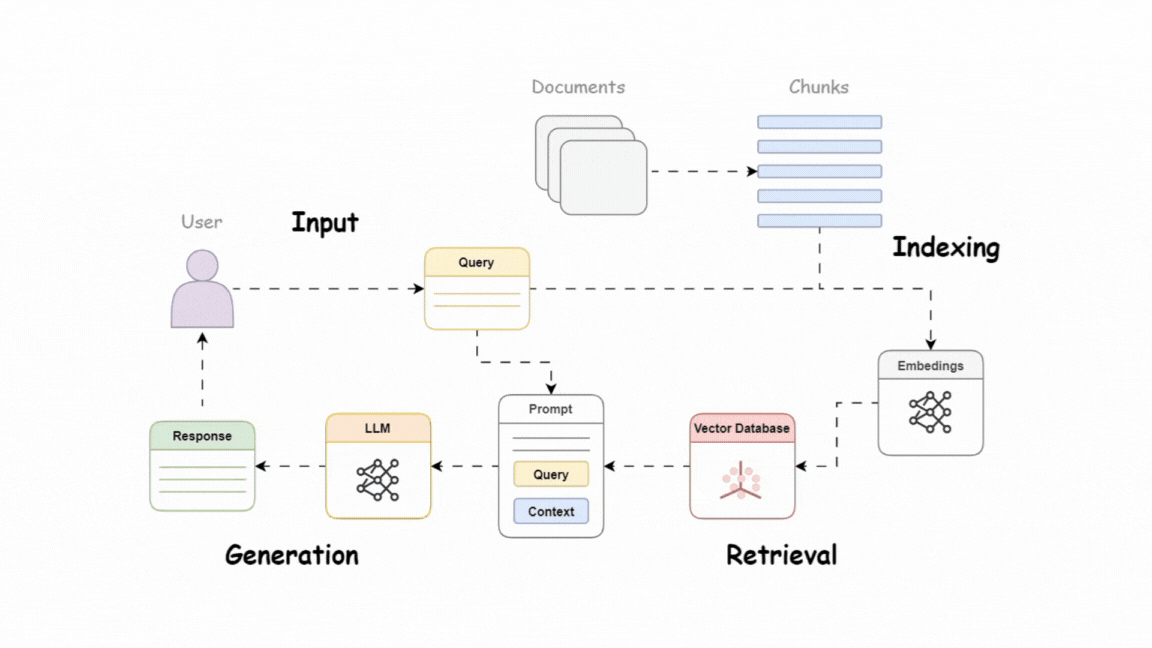
Understanding these components is essential for building an effective RAG system. Each pipeline plays a key role in ensuring the system delivers accurate and relevant answers.
Best Practices for RAG Deployment
Deploying a RAG system successfully requires careful attention to various aspects, including data management, embedding strategies, retrieval optimization, generation processes, and deployment practices.
Below are the best practices to follow:
1. Data Preprocessing
Accurate RAG deployment starts with clean, well-structured, and context-rich data. A strong preprocessing workflow ensures your data is high-quality and relevant, boosting AI performance.
Clean Your Data
- Fix Errors: Correct mistakes and inconsistencies.
- Add Metadata: Enrich data with useful context.
- Remove Duplicates: Eliminate redundancy for cleaner inputs.
- Apply Filters: Use domain-specific rules to keep only what matters.
Preserve Document Structure
Keep the natural hierarchy of documents (titles, sections, etc.) intact to improve chunking and context:
- Add Context with Prefixes: Attach descriptive headers to data chunks for clarity, especially in large documents.
Smart Chunking
Break data into meaningful pieces for better retrieval:
- Use Rolling Windows: Overlap segments to maintain flow.
- Chunk by Elements: Split by headings or paragraphs for context-rich inputs.
With clean, organized, and context-aware data, your RAG system will deliver more accurate and effective results.
Code Example: Advanced Document Parsing with Element-Based Chunking
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
def parse_and_enrich(file_path, chunk_size=500, chunk_overlap=50):
loader = PyPDFLoader(file_path)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", " ", ""]
)
chunks = text_splitter.split_documents(documents)
return chunks
2. Embedding and Vector Management
Embeddings are the backbone of any RAG system, transforming text into vectors that capture semantic meaning for accurate retrieval.
Fine-Tune for Your Domain
Tailoring embedding models to your specific domain boosts accuracy:
- Domain-Specific Models: Fine-tune models like SentenceTransformers to better align with your use case.
- Context-Aware Embeddings: Adjust vectors based on retrieval context for more precise results. For example, the Tabular Embedding Model (TEM) fine-tunes embeddings for tabular data, enhancing performance in specialized applications.
Use Scalable Vector Databases
Leverage advanced vector databases for efficient embedding storage and retrieval:
- Fast Operations: Platforms like Pinecone and Weaviate support high-speed similarity searches across large datasets.
- Seamless Querying: Vector databases are essential for managing and retrieving embeddings in RAG systems.
Add Metadata for Precision
Embedding quality improves with metadata integration:
- Contextual Filters: Include details like document type, author, or date to refine search results.
- Better Understanding: Metadata-enhanced embeddings provide more relevant and context-aware retrievals, especially in complex RAG use cases.
With fine-tuned models, scalable databases, and metadata-rich embeddings, your RAG system will deliver faster, more precise results.
Code Example: Domain-Specific Embedding Pipeline
from sentence_transformers import SentenceTransformer
import pinecone
class EmbeddingPipeline:
def __init__(self, model_name, pinecone_api_key, environment, index_name):
self.model = SentenceTransformer(model_name)
pinecone.init(api_key=pinecone_api_key, environment=environment)
self.index = pinecone.Index(index_name)
def generate_embeddings(self, texts):
embeddings = self.model.encode(texts, convert_to_tensor=True)
return embeddings
def upsert_embeddings(self, ids, embeddings):
vectors = list(zip(ids, embeddings))
self.index.upsert(vectors=vectors)3. Retrieval Optimization
Optimizing retrieval ensures that only the most relevant information reaches the generation pipeline, boosting system performance.
Use Hybrid Retrieval Models
Combine lexical and vector-based search for better recall and precision:
- Lexical + Semantic: Tools like Elasticsearch allow you to mix BM25 scoring with dense embeddings for hybrid searches.
- Built-In Solutions: Platforms like Weaviate offer hybrid search capabilities with adjustable weights for semantic and lexical relevance.
- Precision Boost: These approaches enhance retrieval quality, especially for complex queries.
Apply Re-Ranking Techniques
Refine retrieved results with advanced re-ranking methods:
- RAG Fusion: Use advanced RAG techniques like RAG Fusion to rerank the retrieved documents and improve the results.
- Enhanced Precision: Re-ranking ensures the most contextually relevant results rise to the top.
Use Dynamic Query Reformulation
Make queries smarter to improve recall and precision:
- Sub-Query Decomposition: Break complex queries into simpler parts to target specific aspects of user intent.
- Paraphrasing: Use libraries like Transformers to generate alternative queries for greater retrieval diversity.
- Boosting and Filtering: Elasticsearch features like query boosting and fine-grained filters can further optimize results.
By integrating hybrid models, re-ranking techniques, and dynamic query reformulation, you can ensure precise and context-aware retrieval for your RAG system.
Code Example: Hybrid Retrieval Pipeline
import weaviate
class HybridRetriever:
def __init__(self, client_url):
self.client = weaviate.Client(client_url)
def hybrid_search(self, query, top_k=10):
results = self.client.query.get("Document", ["content", "metadata"]) \
.with_hybrid(query=query, alpha=0.5) \
.with_limit(top_k) \
.do()
return results4. Generation Pipeline
The generation stage transforms retrieved information into actionable insights. Here’s how to make it more effective:
Ground Your Prompts
Keep outputs tied to the retrieved context to reduce hallucinations:
- Context Tagging: Use retrieval-grounded prompts to ensure the model stays aligned with the provided data.
- Factual Accuracy: Align tokens with relevant embeddings to improve reliability and reduce errors.
Optimize Outputs
Prioritize and streamline retrieved data for better generation:
- Relevance Ranking: Use algorithms like Reciprocal Rank Fusion (RRF) to refine chunk relevance.
- Efficient Compression: Apply dimensionality reduction techniques to compress input vectors while preserving semantic meaning, improving speed and quality.
Leverage Few-Shot Learning
Enhance responses with examples tailored to your domain:
- Example-Driven Prompts: Provide specific scenarios to guide the model's outputs.
- In-Context Learning: Use tools like LangChain or OpenAI APIs to structure prompts with examples, ensuring consistent and accurate responses for specialized queries.
By grounding prompts, optimizing outputs, and incorporating few-shot learning, you can significantly improve the quality and relevance of your RAG system's generation stage.
5. Deployment and Monitoring
Once you have a RAG system deployed in production, you need continuous observability and evaluation of your system.
You can use tools specifically designed for this:
Monitoring with LangSmith
LangSmith is a comprehensive developer platform that simplifies every step of the application lifecycle, from logging to observability. It integrates easily with RAG systems, providing robust monitoring with minimal setup.
Key Features of LangSmith:
- Cross-Provider Logging: Supports multiple LLM providers (OpenAI, Azure, Anthropic, etc.).
- Customizable Metadata: Enables detailed tracking through fields like run_name, project_name, session_id, and tags.
- Advanced Observability: Offers a centralized view of performance metrics such as response times, error rates, and system usage.
LangSmith offers a user-friendly interface for tracking and analyzing RAG system performance, making monitoring straightforward and effective.
Monitoring with Athina
Athina is an advanced testing and monitoring platform designed specifically for LLM-powered applications.
It provides real-time monitoring, detailed analytics, and easy evaluations, making it ideal for enhancing RAG system performance and reliability.
Key Features of Athina for RAG Monitoring:
- Cross-Provider Logging: Supports multiple LLM providers (OpenAI, Azure, Anthropic, etc.).
- Metadata Segmentation: Tracks extensive metadata fields such as prompt_slug, customer_id, and expected_response for detailed insights.
- Context Logging: Logs retrieved-context for RAG applications, helping track the quality of retrieval and generation.
- Plug-and-Play Integration: Easy integration using callbacks, reducing setup time.
Athina provides a comprehensive monitoring solution, offering detailed insights into your RAG system's performance and making troubleshooting efficient.
Conclusion
Deploying RAG systems in production involves careful planning and execution across several components, including data management, embedding strategies, retrieval optimization, generation processes, and deployment practices.
By following the best practices outlined in this guide, you can build a robust, scalable, and efficient RAG system capable of delivering accurate and contextually relevant AI responses.
Additionally, using advanced monitoring tools like LangSmith and Athina ensures that your RAG system remains performant and reliable as it scales and adapts to changing data landscapes.
Embrace these practices to fully leverage the potential of RAG systems and drive impactful AI-driven solutions in your organization.


