Difference between Fine Tuning and Prompt Tuning


As AI development teams increasingly leverage pre-trained language models (PLMs) for diverse applications, understanding the nuances of model adaptation techniques becomes crucial. This article provides an in-depth technical comparison of fine-tuning and prompt tuning, specifically tailored for AI engineers, researchers, data scientists, and product developers seeking to optimize PLM performance for downstream tasks.
What is Fine-Tuning?
Fine-tuning, a cornerstone of transfer learning, involves adjusting the weights of a pre-trained language model by training it on a new, task-specific dataset. This process refines the model's ability to perform the desired task by adapting it to the nuances of the new data. For instance, a PLM trained on a general text corpus can be fine-tuned on a dataset of legal documents to excel in named entity recognition.
How Fine-Tuning Works
Fine-tuning typically involves the following steps:
- Select a Pre-Trained Language Model: Choose a PLM suitable for the target task, often leveraging large open-source models trained on extensive text corpora.
- Prepare the Dataset: Gather and prepare a labeled or annotated dataset relevant to the target task.
- Fine-Tune the Model: Train the PLM on the new dataset, adjusting the model's weights to optimize its performance. Employing a lower learning rate enhances stability during this process.
- Evaluate the Model: Assess the fine-tuned model's performance on a held-out test set.
Types of Fine-Tuning
Fine-tuning encompasses various techniques, including:
- Full Fine-Tuning: Updating all the parameters of the pre-trained model.
- Parameter-Efficient Fine-Tuning (PEFT): Updating only a subset of the model's parameters, such as prompt tuning, adapters, and LoRA, to reduce computational costs and training time.
- Knowledge Distillation: Training a smaller model to mimic the behavior of a larger, fine-tuned model.
What is Prompt Tuning?
Prompt tuning, a PEFT technique, involves adding a small set of learnable parameters, called "soft prompts," to the input of the PLM. These soft prompts guide the model towards the desired output without modifying the model's internal weights.
Prompt tuning builds upon the concept of prompt engineering, which involves designing prompts to elicit desired outputs from a language model. While prompt engineering relies on manual crafting, prompt tuning optimizes the prompt format based on model feedback and performance, often through automated or semi-automated methods.
How Prompt Tuning Works
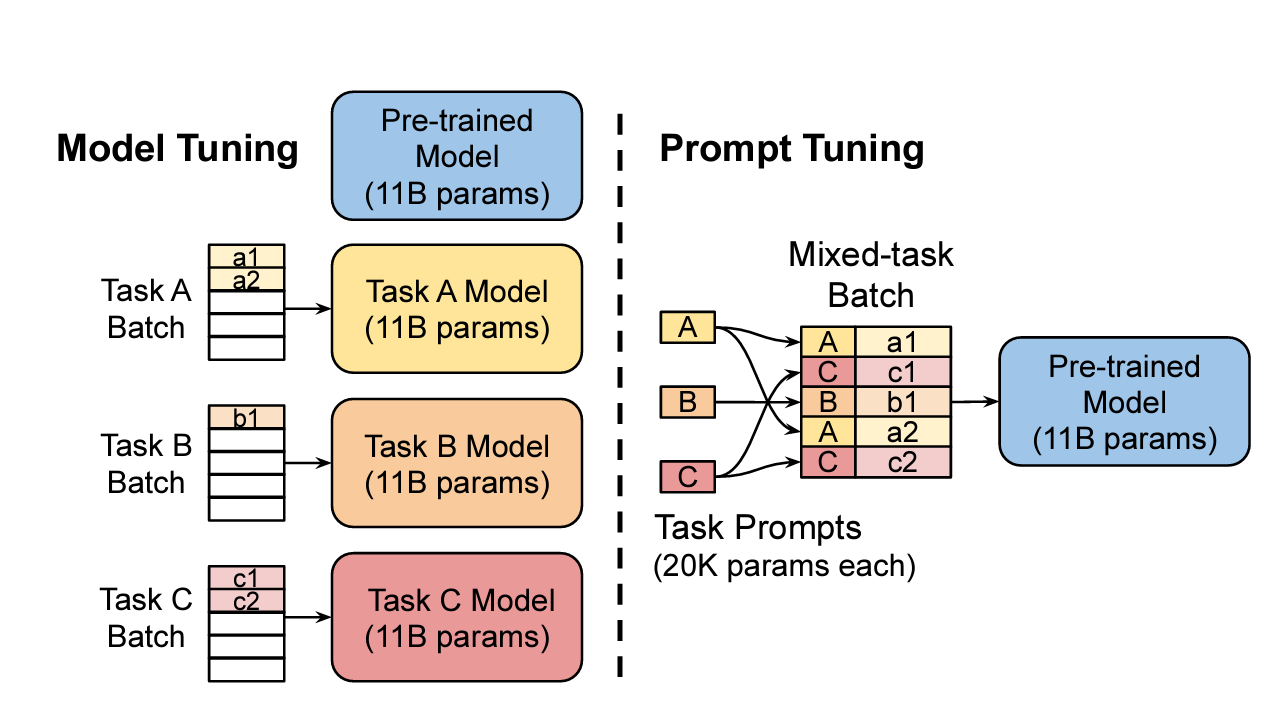
Prompt tuning typically involves these steps:
- Initialize Soft Prompts: Create small vectors of learnable parameters.
- Prepend Soft Prompts to Input: Add the soft prompts to the beginning of the input sequence.
- Train Soft Prompts: Train the soft prompts on the target task dataset, keeping the PLM's parameters frozen.
- Evaluate the Model: Assess the performance of the prompt-tuned model on a held-out test set.
Key Differences Between Fine-Tuning and Prompt Tuning
| Feature | Fine-Tuning | Prompt Tuning |
|---|---|---|
| Parameter Modification | Modifies the weights of the pre-trained model. | Keeps the model's parameters frozen and only adjusts soft prompts. |
| Resource Intensity | More computationally expensive and requires more data. | More efficient and requires less data. |
| Task Specificity | Creates a task-specific model. | Adapts the model to new tasks without creating a separate model for each task. |
| Flexibility | Less flexible across diverse domains. | More flexible and can be easily adapted to new tasks. |
| Deployment | Requires storing and deploying a separate model for each task. | Allows for a single model to be deployed for multiple tasks. |
| Input Format | Maintains the original input format. | Rewrites the input by adding learnable soft prompts. |
| Interpretability | Less interpretable as it modifies the model's internal representations. | More interpretable as the soft prompts provide insights into how the model is guided. |
Advantages and Disadvantages of Fine-Tuning
Advantages:
- High Accuracy: Fine-tuning can lead to significant improvements in accuracy on specific tasks.
- Customization: Allows for extensive customization of the model to specific domains or styles.
- Adaptability: Fine-tuned models can better handle niche topics or recent information not covered in the original training data.
- Reduced Tokens: Fine-tuning can reduce the number of tokens needed in a prompt.
Disadvantages:
- Cost: Fine-tuning requires significant computational resources.
- Data Requirements: Typically requires a large amount of labeled data.
- Overfitting: Fine-tuned models can be prone to overfitting, especially with limited training data.
- Storage: Requires storing a separate copy of the model for each task.
Advantages and Disadvantages of Prompt Tuning
Advantages:
- Efficiency: More efficient than fine-tuning, requiring less computational resources and data.
- Flexibility: Allows for rapid adaptation to new tasks without retraining the entire model.
- Model Integrity: Preserves the integrity of the pre-trained model, retaining its general knowledge and capabilities.
- Reduced Storage: Enables a single model to be deployed for multiple tasks, reducing storage requirements.
- Limited Data: Allows companies with limited data to adapt large models to specific tasks.
Disadvantages:
- Accuracy: May not achieve the same level of accuracy as fine-tuning, especially for complex tasks.
- Prompt Engineering: Designing effective prompts can be challenging.
- Training Time: Requires more training time than fine-tuning, despite being more parameter-efficient.
When to Use Fine-Tuning vs Prompt Tuning
The choice between fine-tuning and prompt tuning depends on factors like the specific task, available resources, and desired accuracy.
| Scenario | Fine-Tuning | Prompt Tuning |
|---|---|---|
| High accuracy required | ✅ | |
| Extensive model customization needed | ✅ | |
| Large amount of labeled data available | ✅ | |
| Computational resources are not a constraint | ✅ | |
| Efficiency and rapid deployment are important | ✅ | |
| Adapting the model to multiple tasks | ✅ | |
| Computational resources are limited | ✅ | |
| Preserving the integrity of the pre-trained model | ✅ |
Impact on AI Development Teams
Prompt tuning offers significant advantages for AI development teams:
- Reduced Computational Costs and Faster Training Times: Allows for quicker experimentation and iteration, accelerating the development cycle.
- Enhanced Model Adaptability and Flexibility: Teams can readily adapt a single model to various tasks, streamlining development and deployment.
- Improved Resource Utilization: Enables efficient use of computational resources, particularly crucial with the increasing size of language models.
- Simplified Model Management: Deploying a single model for multiple tasks reduces storage needs and simplifies model maintenance.
However, prompt tuning may require expertise in prompt engineering to design effective prompts. As the field evolves, new tools and techniques are emerging to facilitate prompt optimization and automate the process.
Design Decisions in Prompt Tuning
Several design decisions affect the performance of prompt tuning:
Prompt Initialization
- Random Initialization: Prompt parameters are initialized with random values.
- Sampled Vocabulary: Prompt tokens are initialized with embeddings from the model's vocabulary.
- Class Label Initialization: For classification tasks, prompt tokens are initialized with embeddings of the output class labels.
Class label initialization generally performs best, but the differences disappear at the XXL model size.
Prompt Length
- Increasing prompt length beyond a single token is essential for good performance. However, there are marginal gains after 20 tokens.
- Larger models, such as XXL, perform well even with single-token prompts.
Pre-training Objective
- T5 models are typically pre-trained with a "span corruption" objective, which is not ideal for prompt tuning.
- Adapting the pre-trained model with a Language Modeling (LM) objective improves prompt tuning performance.
- Longer LM adaptation generally leads to greater gains, but XXL models are robust to shorter adaptations.
Unlearning Span Corruption
- T5 models pre-trained on span corruption may not be ideal for prompt tuning as they have not seen natural text and tend to output sentinel tokens, which are not natural.
- LM adaptation transforms the model to be more similar to models like GPT-3.
- This adaptation helps the model produce realistic text, which responds well to prompts.
Comparison with Similar Approaches
Prefix Tuning
Prefix tuning prepends prefixes to every layer of the transformer network. While effective, it requires more task-specific parameters and a reparameterization of the prefix for stable learning. In contrast, prompt tuning only uses a single prompt representation at the input layer.
WARP
WARP adds prompt parameters to the input layer and uses a learnable output layer to project the mask to class logits. This approach is limited to classification tasks. Prompt tuning does not require any changes to the input or a task-specific head.
P-tuning
P-tuning interleaves learnable continuous prompts throughout the embedded input. It requires joint updates to both the prompt and the model parameters. Prompt tuning keeps the original language model frozen.
Adapters
Adapters are small bottleneck layers inserted between frozen network layers. They modify the function that acts on the input representation, whereas prompt tuning modifies behavior by adding new input representations.
Conclusion
Fine-tuning and prompt tuning are valuable techniques for adapting PLMs to specific tasks. Fine-tuning offers high accuracy and customization but demands more resources. Prompt tuning provides efficiency and flexibility with lower resource requirements, making it increasingly attractive for AI development teams. As NLP progresses and PLMs grow larger, prompt tuning and other PEFT techniques will likely play a pivotal role in enabling efficient and effective model adaptation for a wide range of AI applications.


