Grouped-Query Attention: Enhancing AI Model Efficiency

Why AI Efficiency Matters
Artificial intelligence (AI) models, particularly those used in natural language processing (NLP) and computer vision, have become increasingly complex, requiring vast computational resources to maintain high performance.
As models like transformers dominate the AI landscape, their ability to process large datasets and deliver accurate results comes at a steep cost: high computational load, increased memory usage, and latency.
Traditional AI models often need help with scalability issues. These models demand extensive memory and processing power, which limits their deployment in real-time applications or resource-constrained environments.
In fields such as healthcare, finance, and e-commerce, where real-time AI processing is critical, optimizing AI model efficiency is essential to ensure both performance and feasibility.
Grouped-query attention (GQA) emerges as a solution to these challenges by introducing a more efficient method for handling attention mechanisms in transformers.
It reduces the computational overhead while maintaining high accuracy, making AI models more scalable and cost-effective. In this article, we explore the workings of GQA, its impact on AI model efficiency, and how it represents a significant step forward in transformer optimization.
Understanding Attention Mechanisms in AI
Attention mechanisms lie at the heart of transformer models, enabling them to process input sequences by focusing on the most relevant parts of the data.
Self-attention allows the model to weigh different tokens in a sequence and understand their relationships, making it particularly effective for tasks that involve context, such as translation and text summarization.
In traditional self-attention, each input token attends to every other token in the sequence, generating attention scores. While this process significantly improves model performance, it introduces a significant challenge: quadratic complexity about the sequence length.
As the input size grows, attention calculations increase dramatically, leading to high computational costs and memory requirements.
For models like GPT-3 and BERT, which process vast amounts of data, the scalability of self attention becomes a limiting factor. The introduction of Grouped-Query Attention (GQA) addresses this limitation by optimizing how queries are processed in the attention mechanism.
What is Grouped-Query Attention?
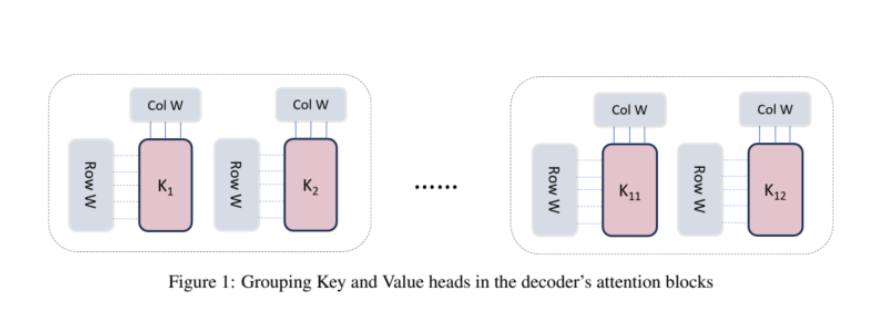
Grouped-query attention (GQA) is an innovative variation of the traditional self-attention mechanism that optimizes how queries are processed within transformer models.
Instead of processing each query head independently, GQA groups similar queries together, allowing multiple queries to share the same key-value pairs. This results in fewer computations and a more efficient use of memory.

In traditional attention mechanisms, each query head processes its queries separately, leading to redundant calculations. GQA simplifies this process by clustering queries into groups based on their similarity. These groups then share key-value pairs, drastically reducing the required calculations.
For example, each query computes attention scores with all key-value pairs in a typical self-attention mechanism. In contrast, GQA reduces this burden by grouping the queries, thereby minimizing the number of distinct key-value computations.
This approach leads to significant reductions in both memory usage and computational time.
How Grouped-Query Attention Enhances AI Model Efficiency
GQA improves AI model efficiency by addressing the bottlenecks inherent in traditional self- attention mechanisms. Here’s how it optimizes AI models:
- Reduced Computational Load: By reducing the unique key-value pairs needed for each query head, GQA lowers the overall number of calculations during inference. This reduces processing time for each query, making the model faster and more efficient.
- Memory Optimization: Traditional self-attention mechanisms require significant memory to store the attention scores for each query head. GQA, by grouping similar queries, reduces the memory footprint, making it easier to scale models to handle larger datasets and longer sequences. This is especially beneficial for tasks that involve long-range dependencies, such as machine translation or document summarization.
- Latency Reduction: With fewer key-value pairs to compute, models using GQA experience a noticeable decrease in latency. This is crucial for real-time applications, where slight delays can impact performance. For example, in conversational AI systems, GQA enables the model to generate responses more quickly, improving user experience.
- Improved Throughput: By optimizing the attention mechanism, GQA increases the model’s
throughput, allowing it to handle more requests or larger batches of data simultaneously. This
makes it ideal for large-scale deployments, where efficiency and speed are paramount.
Performance Benchmarks: Studies show that models using GQA achieve up to 50% reductions in memory usage and 30-40% improvements in processing speed compared to traditional self-attention mechanisms. These improvements make GQA a valuable tool for optimizing AI models, especially in environments where resources are limited.
Applications and Use Cases

The benefits of GQA extend across a wide range of industries and AI applications. Here are some
examples where GQA can significantly improve model efficiency:
- Natural Language Processing (NLP): GQA is particularly useful in NLP tasks like text summarization, machine translation, and sentiment analysis, where long input sequences must be processed efficiently. By reducing the memory and computational requirements, GQA enables NLP models to handle larger datasets and provide faster results.
- Computer Vision: In image recognition and object detection tasks, GQA allows AI models to process visual data more quickly, making it ideal for real-time applications like autonomous driving and video surveillance. The reduced computational load and memory requirements ensure these models can operate in resource-constrained environments.
- Healthcare: AI-driven systems in healthcare, such as medical imaging analysis or predictive diagnostics, can benefit from GQA’s ability to process large amounts of data with reduced latency. This ensures that critical healthcare decisions can be made faster, improving patient outcomes.
- Finance: In the finance industry, where real-time decision-making is critical, GQA enables AI models to process large datasets quickly, making it ideal for fraud detection, risk analysis, and automated trading systems.
Comparison: Grouped-Query Attention vs. Other Optimization Techniques
GQA is not the only optimization technique for improving AI model efficiency, but it stands out due to its ability to reduce computational overhead without sacrificing accuracy.
Here’s how GQA compares to other methods:
- Multi-Query Attention (MQA): GQA and MQA aim to reduce the number of key-value pairs processed by the model. However, GQA further groups similar queries, leading to more significant memory and computational savings.
- Sparse Attention: While sparse attention reduces the complexity of attention mechanisms by selectively attending to certain parts of the input, it may miss essential relationships between tokens. GQA, on the other hand, maintains high accuracy by grouping queries without losing critical contextual information.
- Low-Rank Attention: This technique reduces the dimensionality of the attention mechanism, which can save computational resources but may lead to a drop in model accuracy. GQA balances efficiency and accuracy, making it a more versatile solution.
In scenarios where real-time processing and scalability are priorities, GQA offers the best balance
between speed, memory efficiency, and accuracy.
Future of AI Efficiency: Grouped-Query Attention and Beyond

The future of AI model efficiency lies in the continued development and refinement of attention mechanisms like GQA.
As complex models grow, the need for efficient processing will only increase. GQA represents a significant step forward, but there is room for improvement.
One potential development area is the integration of GQA with other optimization techniques, such as dynamic or memory-efficient attention.
This could lead to even more significant computational costs and memory usage reductions, allowing AI models to handle even larger datasets and more complex tasks.
Additionally, as edge computing becomes more prevalent, GQA will enable AI deployment on resource-constrained devices.
By reducing attention mechanisms' computational and memory requirements, GQA makes it possible to deploy powerful AI models on devices with limited resources, such as smartphones or IoT devices.
Conclusion: Driving the Future of Efficient AI Models
Grouped-query attention (GQA) represents a significant advancement in AI, providing a practical solution to the growing computational demands of large-scale transformers.
By optimizing how queries are processed in attention mechanisms, GQA significantly reduces memory consumption and computational load, enabling faster and more scalable AI systems.
As AI continues to evolve, GQA and similar optimization techniques will be crucial in driving the next wave of efficient AI models, making them more accessible and cost-effective for various industries.
For AI practitioners, exploring GQA and its applications will be essential for staying at the forefront of AI 1innovation.