Top 10 LLM Benchmarking Evals


Large Language Models (LLMs) have transformed artificial intelligence by understanding and generating human-like text. For AI development teams—including engineers, researchers, data scientists, and product developers—accurately assessing these models is vital. Benchmarking evaluations offer insights into the strengths and weaknesses of different LLMs, guiding further research and development. Drawing from reliable sources like Stanford HELM, PapersWithCode, and Hugging Face, this article explores the top 10 LLM benchmarking evaluations, summarizing their key metrics, methods, and results.
1. HumanEval
HumanEval is a popular benchmark that tests the code generation skills of LLMs. It includes 164 carefully designed programming problems. Each problem comes with a function signature, docstring, body, and unit tests. These problems check if a model can create code that is both syntactically correct and functionally accurate.
Evaluation Methodology
HumanEval emphasizes functional correctness over traditional text-matching metrics. It uses the pass@k metric, which measures the chance that at least one of the top k generated code samples for a problem passes all unit tests. This method mimics how human developers evaluate code, focusing on producing working solutions.
HumanEval is a key benchmark in LLM evaluation. Its pass@k metric is widely used in competitive settings like the Papers with Code leaderboard. This focus on functional correctness has pushed the development of LLMs that can effectively solve programming challenges.
2. Open LLM Leaderboard
Hosted by Hugging Face, the Open LLM Leaderboard is an automated system that tracks, ranks, and evaluates open-source LLMs and chatbots. The leaderboard was created to highlight state-of-the-art models and track progress within the open-source community. It helps AI development teams identify top-performing models and make informed decisions for their projects.
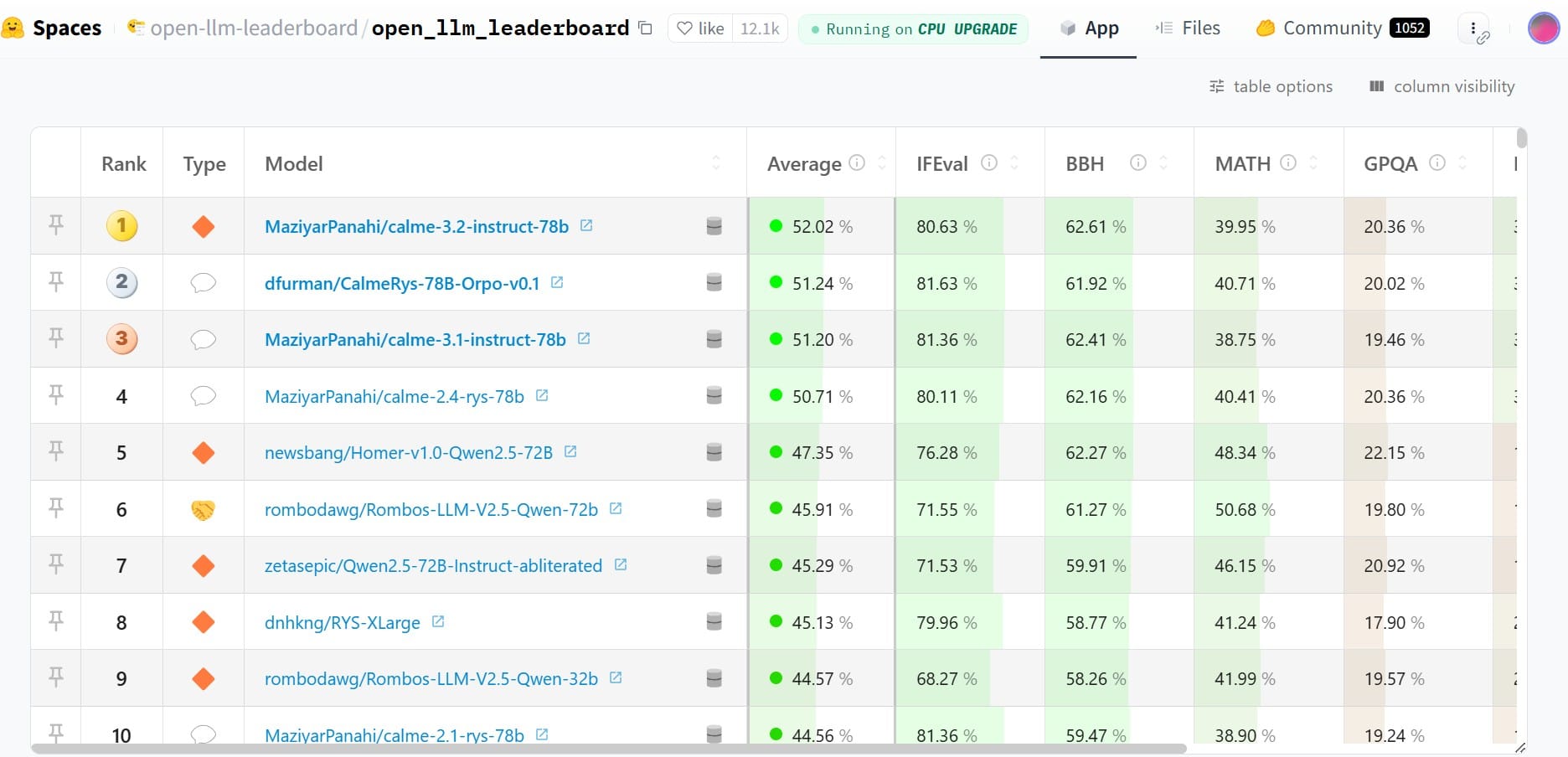
Evaluation Methodology
The leaderboard evaluates models on six benchmarks, each designed to test different aspects of language model capabilities:
- IFEval (Paper):
IFEval assesses a model’s ability to follow explicit instructions, such as including specific keywords or adhering to a particular format. It emphasizes strict compliance with formatting guidelines rather than the quality of the generated content, utilizing precise metrics to measure adherence. - BBH (Big Bench Hard) (Paper):
BBH is a subset of 23 challenging tasks from the BigBench dataset. It evaluates models on complex reasoning, including multistep arithmetic, algorithmic tasks (e.g., boolean expressions, SVG shapes), language understanding (e.g., sarcasm detection, name disambiguation), and comprehensive world knowledge. BBH's performance aligns well with human preferences, providing deep insights into model capabilities. - MATH Lvl 5 (Paper):
MATH Lvl 5 comprises high-school level competition math problems formatted consistently with LaTeX for equations and Asymptote for figures. This subset focuses on level 5 questions to maintain high difficulty, requiring models to perform precise calculations and multi-step reasoning to achieve exact matches in their solutions. - GPQA (Graduate-Level Google-Proof Q&A Benchmark) (Paper):
GPQA features graduate-level questions crafted by PhD experts in fields like biology, physics, and chemistry. Designed to be challenging for non-experts, GPQA ensures high factual accuracy and difficulty through multiple validation rounds. Access is restricted to prevent data contamination, ensuring the benchmark remains robust and reliable. - MuSR (Multistep Soft Reasoning) (Paper):
MuSR consists of algorithmically generated complex problems, including murder mysteries, object placement scenarios, and team allocation optimizations. Each problem is approximately 1,000 words long, requiring models to integrate reasoning with long-range context parsing. Most models perform near random, highlighting MuSR's difficulty and its ability to test advanced reasoning capabilities. - MMLU-PRO (Massive Multitask Language Understanding - Professional) (Paper):
MMLU-PRO is an enhanced version of the standard MMLU dataset, addressing previous issues like noisy data and reduced difficulty due to model advancements. It features 10-choice questions that demand deeper reasoning and has been meticulously reviewed by experts to minimize noise. This makes MMLU-PRO a higher-quality and more challenging benchmark for assessing professional multitask language understanding.
Higher scores across these benchmarks indicate better performance, providing a comprehensive assessment of models' reasoning and knowledge across diverse domains in both 0-shot and few-shot settings.
Reproducibility
To ensure that results are reproducible, the Open LLM Leaderboard provides a fork of the lm_eval repository. Follow these steps to reproduce the results:
git clone git@github.com:huggingface/lm-evaluation-harness.git
cd lm-evaluation-harness
git checkout main
pip install -e .
lm-eval --model_args="pretrained=<your_model>,revision=<your_model_revision>,dtype=<model_dtype>" --tasks=leaderboard --batch_size=auto --output_path=<output_path>Attention: For instruction models, add the --apply_chat_template and --fewshot_as_multiturn options. Note that results may vary slightly with different batch sizes due to padding.
By leveraging the Open LLM Leaderboard, AI development teams can stay informed about the latest advancements in open-source LLMs, make data-driven decisions when selecting models, and contribute to the community’s understanding of model performance and capabilities.
3. ARC (AI2 Reasoning Challenge)
The AI2 Reasoning Challenge (ARC) is a benchmark that assesses the reasoning abilities of LLMs within scientific contexts. It features grade-school science questions in a multiple-choice format, requiring models to analyze and choose the best answers.
Example Question
Question: Which statement correctly describes a physical characteristic of the Moon?
Answer Choices:
- A: The Moon is made of hot gases.
- B: The Moon is covered with many craters.
- C: The Moon has many bodies of liquid water.
- D: The Moon has the ability to give off its own light.
Correct Answer: B
ARC measures a model's ability to use knowledge and reasoning to solve problems that need an understanding of scientific concepts. This is essential for evaluating whether LLMs can comprehend and reason about scientific information effectively.
4. HellaSwag
HellaSwag is a benchmark that tests commonsense reasoning in LLMs. It challenges models to understand everyday scenarios and make logical inferences by completing incomplete sentences.
Example Question
Incomplete Sentence: The chef poured the batter into the...
Answer Choices:
- oven and baked it.
- pan and flipped it.
- bowl and stirred it.
- sink and washed it.
Correct Answer: pan and flipped it.
HellaSwag is tough for LLMs because it requires understanding implicit knowledge and reasoning about daily situations. While humans typically score around 95%, the best LLMs, like Falcon with 180 billion parameters, achieve about 88.89%. This gap shows the ongoing challenge of matching human-level commonsense reasoning in LLMs.
5. MMLU (Massive Multitask Language Understanding)
MMLU is a broad benchmark that evaluates LLMs across 57 subjects, including STEM, humanities, social sciences, and more. It includes tasks like elementary math, US history, computer science, and law.
Evaluation Methodology
MMLU employs a rigorous and structured methodology to provide an in-depth assessment of an LLM's proficiency in various domains:
- Dataset Composition:
MMLU consists of approximately 10,000 multiple-choice questions derived from undergraduate and professional exams. These questions are meticulously curated to cover 57 subjects, ensuring a balanced representation of different fields such as:- STEM: Includes subjects like mathematics, physics, chemistry, and computer science.
- Humanities: Encompasses history, literature, philosophy, and languages.
- Social Sciences: Covers psychology, economics, political science, and sociology.
- Professional Fields: Includes law, medicine, and business.
- Question Structure:
Each question is formatted as a multiple-choice prompt with four answer options (A, B, C, D). This standardized format facilitates consistent evaluation across different subjects and ensures that models are tested on their ability to discern the correct answer from plausible alternatives. - Shot Settings:
MMLU supports both zero-shot and few-shot evaluation paradigms:- Zero-Shot: Models receive each question without any prior context or examples, testing their ability to recall and apply knowledge independently.
- Few-Shot: Models are provided with a limited number of exemplars (typically 5) before answering test questions, assessing their ability to generalize from a small set of examples.
- Scoring Metrics:
Performance is primarily measured using accuracy, defined as the percentage of correctly answered questions. Additionally, MMLU may utilize normalized accuracy to account for variations in question difficulty across different subjects, providing a more nuanced evaluation of model performance. - Task Diversification:
The benchmark includes a variety of task types within each subject to assess different cognitive skills:- Factual Recall: Questions that require memorization of specific facts or data.
- Comprehension: Questions that test understanding of concepts and principles.
- Application: Scenarios that require applying knowledge to solve problems.
- Analysis and Synthesis: Complex questions that involve critical thinking and integration of multiple concepts.
- Data Preprocessing:
All questions are standardized in terms of formatting, language, and structure to ensure consistency. This includes uniform labeling of answer choices and clear delineation between questions and options, which helps in minimizing biases and ensuring fair comparisons across different models. - Benchmarking Protocol:
Evaluations are conducted using the Eleuther AI Language Model Evaluation Harness, ensuring reproducibility and consistency. Models are tested under controlled conditions, with standardized tokenization and input handling to maintain uniformity across evaluations.
6. TruthfulQA
TruthfulQA measures the truthfulness and reliability of LLMs. It focuses on whether models can distinguish between true and false statements, even when false statements are plausible or widely believed.
Evaluation Methodology
TruthfulQA presents models with questions that require factual accuracy and an understanding of truthfulness. This ensures that LLMs provide reliable information and avoid generating misleading or incorrect content, which is crucial for maintaining trust in AI applications.
7. Winogrande
Winogrande tests LLMs' ability to resolve coreference and pronoun disambiguation. It provides short scenarios with pronouns and asks models to identify the correct referent, assessing their understanding of context and ability to resolve language ambiguities.
Example Question
Sentence: The city councilmen refused the demonstrators a permit because they advocated violence.
Task: Identify the correct referent of "they."
Winogrande pushes LLMs to move beyond simple word matching, demonstrating a deeper understanding of word and phrase relationships in context. This is essential for accurate interpretation and generation of human-like text.
8. GSM8K (Grade School Math)
GSM8K evaluates the mathematical reasoning abilities of LLMs using grade-school math word problems. These problems require multi-step reasoning and calculations to find the correct answer.
Evaluation Methodology
GSM8K presents models with math word problems and prompts them to provide step-by-step solutions. This approach encourages models to show their reasoning process, ensuring they can solve math problems expressed in natural language effectively.
9. BigCodeBench
BigCodeBench assesses the code generation capabilities of LLMs in realistic settings. It challenges models to use multiple function calls from 139 libraries across 7 domains in 1,140 detailed tasks. Each task includes 5.6 test cases with an average branch coverage of 99% to rigorously evaluate the generated code.
Variants
- BigCodeBench-Complete: Presents complex programming tasks that require diverse function calls and library usage. It assesses the model's ability to understand instructions, generate correct code, and produce functional solutions.
- BigCodeBench-Instruct: Focuses on generating code from natural language instructions. It requires models to produce code that meets specified requirements based on concise instructions.
Evaluation Metrics
BigCodeBench uses the pass@1 metric, measuring whether the first generated code sample passes all test cases. This ensures high standards for code functionality and reliability.
10. Stanford HELM
The Holistic Evaluation of Language Models (HELM), developed by Stanford University, is a comprehensive benchmarking framework. It assesses LLMs across various dimensions beyond just accuracy, emphasizing transparency and standardization in evaluation practices.
Evaluation Scenarios
- Core Scenarios: Test fundamental LLM capabilities like question answering, summarization, and translation.
- Stress Tests: Evaluate the model's robustness and ability to handle challenging or unexpected inputs.
- Fairness Evaluations: Examine the model's biases and potential for generating unfair or discriminatory outputs.
By including these scenarios, HELM provides a well-rounded evaluation of LLMs, helping researchers identify areas for improvement and ensure responsible development.
Synthesis
The top 10 LLM benchmarking evaluations offer a broad view of current LLM capabilities and limitations. They cover a wide range of tasks, from basic reasoning and common sense to complex problem-solving and code generation.
Key Trends
- Functional Correctness and Real-World Applicability: Evaluations like HumanEval and BigCodeBench focus on whether LLMs can generate functional code, moving beyond text-matching metrics. This shift highlights the growing importance of LLMs in practical applications and the need for reliable performance in real-world tasks.
- Holistic Assessments: Benchmarks like MMLU and Stanford HELM aim for comprehensive evaluations across diverse domains. This approach provides a complete understanding of an LLM's strengths and areas needing improvement.
Importance for AI Development Teams
For AI development teams, these benchmarking evaluations are essential tools for:
- Assessing Model Performance: Understanding the strengths and weaknesses of different LLMs to choose the best models for specific tasks.
- Guiding Research and Development: Identifying areas where models excel or need improvement, informing future research and development efforts.
- Ensuring Reliability and Trustworthiness: Evaluating aspects like truthfulness and fairness to ensure deployed models provide reliable and unbiased outputs.
Future Directions
Continued development of robust and comprehensive evaluations is crucial to keep up with rapid advancements in LLMs. Future research should address current benchmarks' limitations, such as the potential for overfitting and the need for more nuanced metrics that capture the full range of LLM capabilities. By refining and expanding evaluation methods, AI development teams can ensure LLMs are developed and deployed to maximize their benefits while minimizing potential risks.


