A Comprehensive Guide to Different RAG Architectures


Introduction
In an era where data doubles every two years, sifting through mountains of information to find exactly what you need can feel like searching for a needle in an ever-expanding haystack.
Yet, this is the challenge that modern artificial intelligence (AI) systems, like Retrieval-Augmented Generation (RAG), are designed to tackle.
Search engines might be among the first to face obsolescence from AI, with products like SearchGPT and Perplexity leading the charge. These systems rely on RAG, and the tools to build them are now within anyone's reach.
But what sets apart a basic RAG system from an optimized one? The difference often lies in how well it's tailored to the task.
This guide will explore the spectrum of RAG architectures, diving deep into the techniques that enhance their performance.
Overview of RAG
The acronym RAG originates from the 2020 paper, Retrieval-Augmented Generation for Knowledge-Intensive Tasks, published by Facebook AI Research (now Meta AI).
This paper characterizes RAG as “a general-purpose fine-tuning recipe” designed to integrate any large language model (LLM) with various internal or external knowledge sources.
RAG gives an LLM a superpower: the ability to consult an external knowledge base before crafting its responses. LLM alone, no doubt, is super bright but faces several challenges:
- Presenting False Information: When the LLM lacks the answer, it might generate incorrect or misleading responses.
- Providing Out-of-Date Information: LLMs can offer generic or outdated answers, especially when users expect current and specific information.
- Relying on Non-Authoritative Sources: The model may draw on sources that are not credible or accurate.
- Confusing Terminology: Different sources might use the same terms differently, leading to misunderstandings or inaccurate responses.
RAG helps address these issues by anchoring the LLM's responses in authoritative and current knowledge, ensuring more reliable and relevant interactions.
So, imagine your LLM as a brilliant but forgetful scholar—by tapping into up-to-date sources, it can offer accurate, contextually relevant answers without needing a complete retrain.
The core components of the RAG pipeline are:
- Retrieval Pipeline: Retrieves relevant documents or data from an external knowledge base.
- Generation Pipeline: Uses the retrieved information to generate contextually accurate and relevant responses.
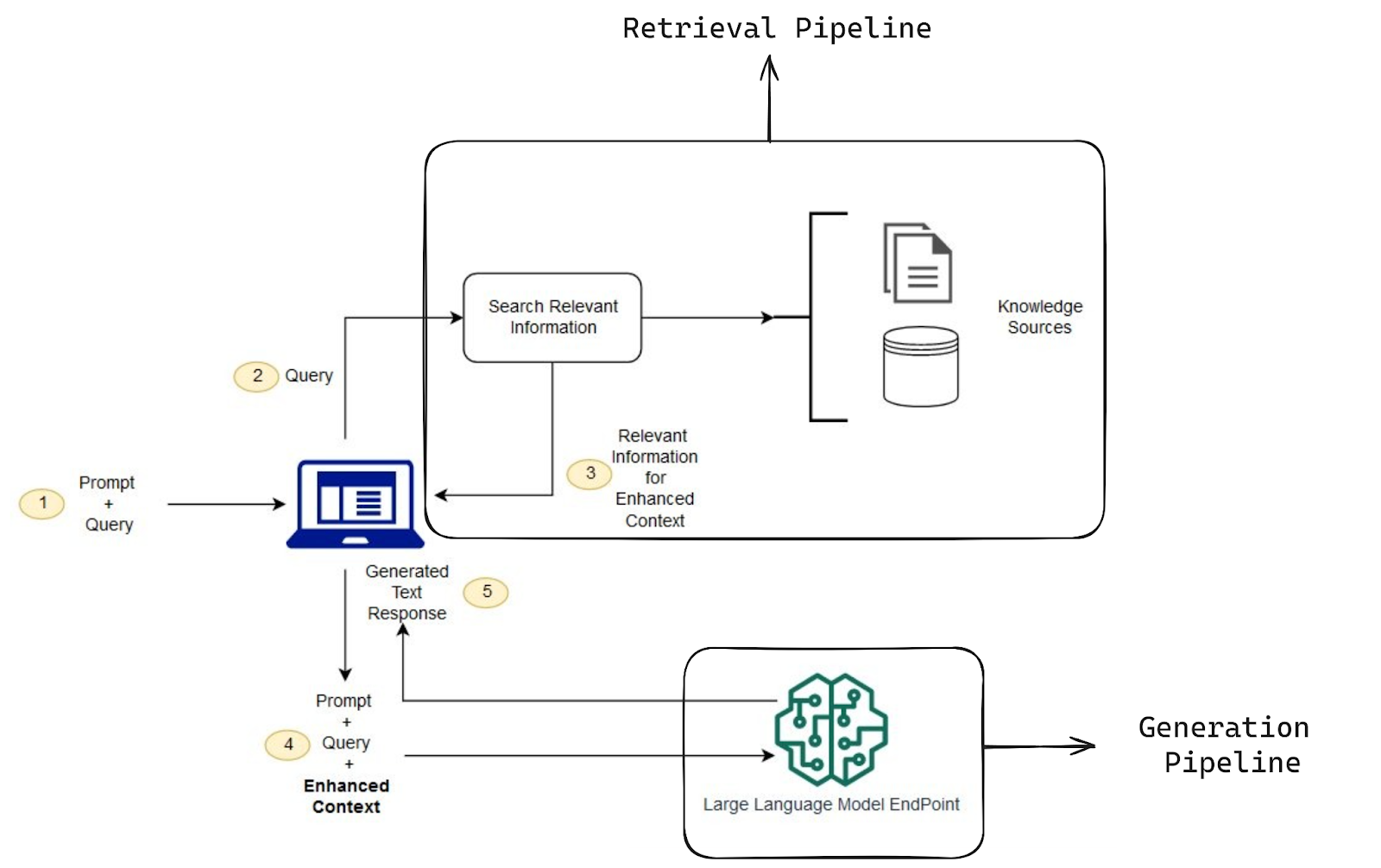
Fig 1: A fundamental architecture of Retrieval-Augmented Generation (RAG)
However, basic RAG has significant room for improvement, which will be explored in the next section, and potential solutions.
Types of RAG Architectures
Before jumping straight to the types of architecture of RAG, let’s discuss the challenges that a primary RAG faces:
- Basic RAG often struggles with queries that span multiple domains or topics, leading to mismatches in retrieved documents and reduced accuracy.
- The reliance on vector similarity alone can cause irrelevant or suboptimal document retrieval, especially for nuanced queries.
- Basic RAG systems may have higher latency due to inefficient retrieval and processing steps.
- The broad context windows in basic RAG can overwhelm the LLM with irrelevant information, reducing the quality of the generated response.
- The standard RAG approach may not effectively break down or handle multi-faceted queries.
- The lack of advanced filtering and indexing can cause higher processing costs, especially when handling large datasets or frequent queries.
The architectures presented ahead solves such problems. Let’s look at them.
Query Enhancement
Basic RAG does reflect the true self of the user query, and it might lead to incompetent results. Query enhancement adjusts and refines the RAG input query process to capture and convey the query's intent accurately. Let’s see some techniques:
1. Hypothetical Questions
This approach uses an LLM to generate potential user questions about the content of each document chunk.
Before the user's query reaches the LLM, the vector store retrieves the most relevant hypothetical questions related to the actual query and their corresponding document chunks and forwards them to the LLM.
This method addresses the cross-domain asymmetry (will be discussed later) issue in vector search. It enables query-to-query matching, thereby reducing the reliance on vector searches.
Workflow for Generating Hypothetical Questions
- Generate Hypothetical Questions: Use the LLM to create a set of hypothetical questions based on the content of the document chunks.
- Store in Vector Store: Save the generated hypothetical questions along with their corresponding document chunks in the vector store.
- Retrieve Relevant Data: Query the vector store to find the most relevant hypothetical questions and document chunks based on the user query.
- Generate Final Response: Send the retrieved hypothetical questions and document chunks to the LLM to generate the final response to the user query.
2. HyDE
The acronym HyDE stands for Hypothetical Document Embeddings. Instead of contextual information, this approach uses LLM to create “Hypothetical Documents” or simulated responses to a user query.
The answer is then translated into vector embeddings, which are utilized to find the most suitable parts of a document in a vector database.
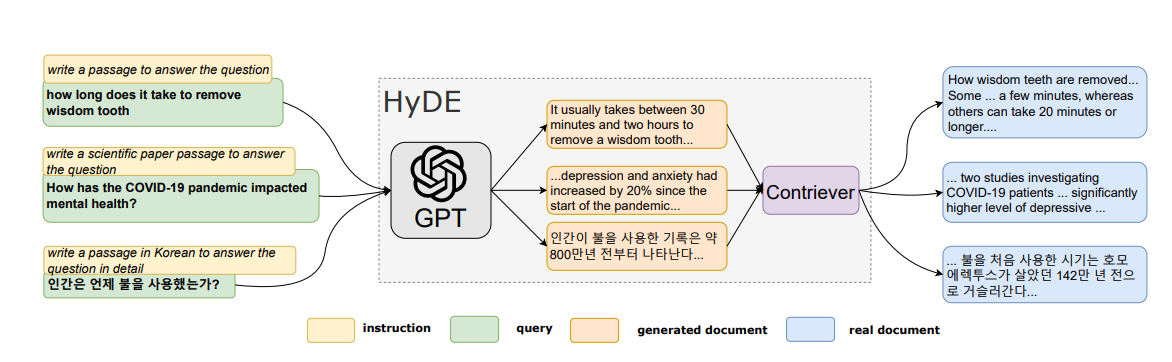
Fig 2: An illustration of the HyDE model.
The vector database returns the most relevant K chunks and sends them back to LLM with user query text to generate the final answer. However, this method increases computational costs and uncertainties when generating hypothetical answers.
Workflow for Generating Hypothetical Document
- Generate Hypothetical Document: Create a simulated document or fake answer using the LLM based on the user query.
- Convert to Embeddings: Transform the hypothetical document into vector embeddings.
- Retrieve Relevant Chunks: Use the vector embeddings to search the vector database and retrieve the top-K most relevant document chunks.
- Generate Final Response: To generate the final response, provide the retrieved document chunks and the original query to the LLM.
This improves the query process because vector databases, serving as knowledge hubs, match documents more effectively than questions.
3. Sub-Queries
When tackling a complex user query, an LLM can break it into bite-sized, manageable sub-queries. Imagine a user asking, “What are the key differences between AWS and Azure?”
Instead of answering this all at once, the LLM might split it into more straightforward questions like, “What features does AWS offer?” and “What features does Azure provide?”
These sub-queries are then turned into vector embeddings and sent to the vector database. The database retrieves the top-K most relevant document chunks for each subquery.
With this tailored information, the LLM crafts a detailed and precise answer.
Workflow for Sub-Queries
- Break Down Query: The LLM decomposes the complex user query into simpler sub-queries.
- Convert to Embeddings: Transform each subquery into vector embeddings.
- Retrieve Relevant Chunks: Search the vector database for each sub-query's Top-K most relevant document chunks.
- Generate Final Response: To generate the final response, provide the retrieved document chunks and the original query to the LLM.
Indexing Enhancement
Indexing enhancement involves optimizing how data is organized and retrieved to boost the performance of RAG. Here are some top techniques that can improve it:
1. Merging Document Chunks Automatically
This technique involves organizing document data into two levels: child chunks (detailed segments) and their corresponding parent chunks (broader summaries).
Initially, the system searches for detailed child chunks. When a sufficient number of child chunks from a set belong to the same parent chunk, the parent chunk is used to provide contextual information to the LLM.
Imagine your document library as a well-organized bookshelf with detailed notes and overarching summaries. To make searching more efficient, locate detailed notes (child chunks) and merge related notes into a broader summary (parent chunks).
This way, when you search, you find specific notes and get the broader context from associated summaries.
Workflow for Merging Document Chunks Automatically
- Index Chunks: Index child chunks (detailed segments) and parent chunks (broader summaries).
- Retrieve Child Chunks: Search and retrieve relevant child chunks based on the user query.
- Merge Chunks: Consolidate child chunks into their corresponding parent chunks if a specified threshold is met.
- Generate Final Response: Provide the merged parent chunks as contextual information to the LLM to generate the final response.
2. Constructing Hierarchical Indices
This method involves creating a two-tier indexing system: one for document summaries and another for individual document chunks.
The retrieval process consists of two stages: filtering relevant documents based on their summaries and then retrieving the document chunks within those selected documents.
Workflow for Constructing Hierarchical Indices
- Create Indices: Establish two-level indices: one for document summaries and another for document chunks.
- Retrieve Relevant Documents: Search for and obtain relevant documents based on the summaries.
- Retrieve Document Chunks: Extract the document chunks from the relevant documents.
- Generate Final Response: Use the retrieved document chunks to generate the final response with the LLM.
3. Hybrid Retrieval and Reranking
The Hybrid Retrieval and Reranking technique combines multiple retrieval methods to enhance search performance.
Initially, vector similarity retrieval is used alongside supplementary retrieval methods, such as linguistic frequency-based approaches or sparse embedding models.
After obtaining initial results, a reranking process prioritizes them based on their relevance to the user query.
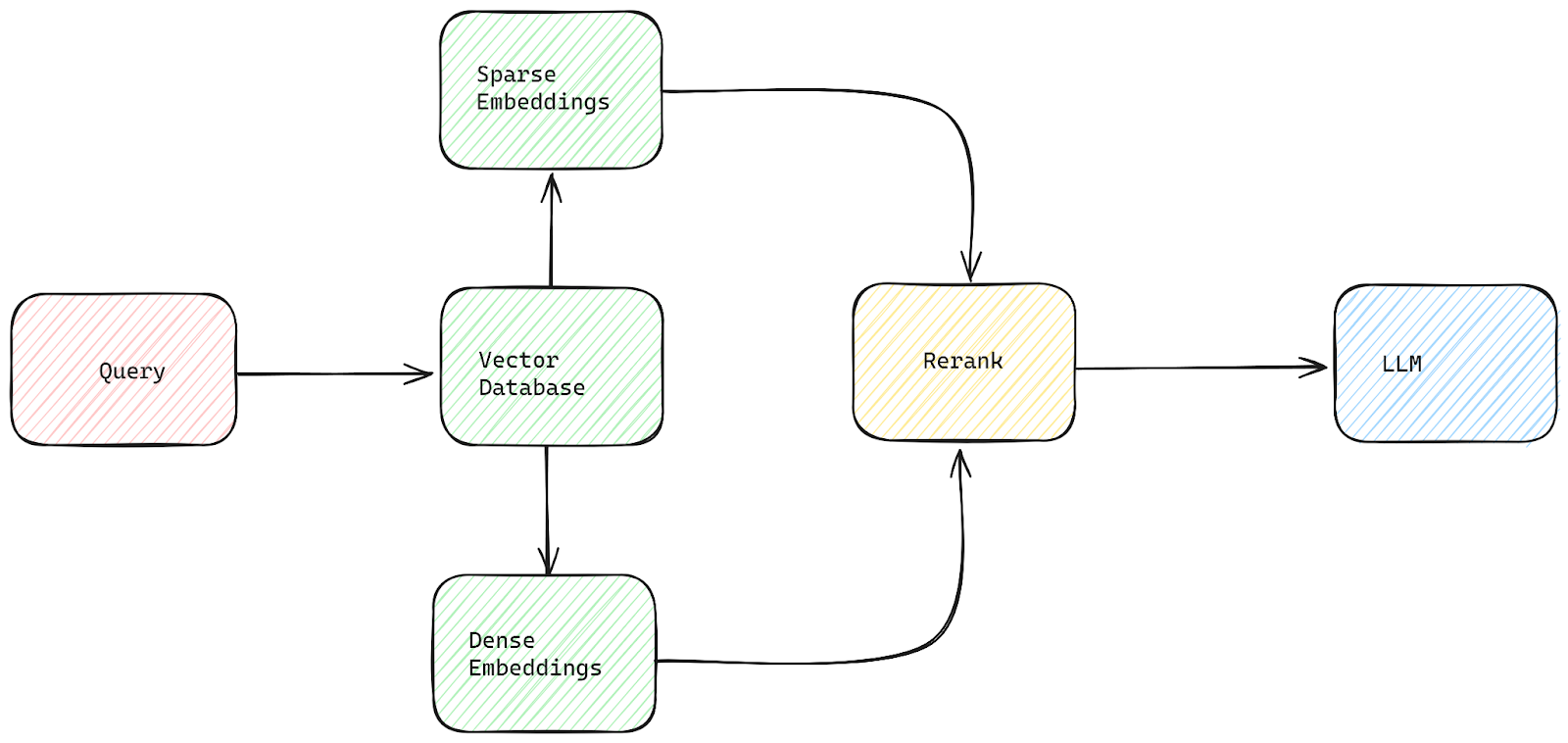
Fig 3: A basic hybrid retrieval and reranking approach
Workflow for Hybrid Retrieval and Reranking
- Perform Initial Retrieval:
- Obtain initial results using vector similarity methods (e.g., using embeddings to find similar documents).
- Obtain initial results using traditional methods like BM25 or frequency-based approaches.
- Combine Results: Merge the results from vector similarity and lexical retrieval methods into a unified set.
- Rerank Results: Apply a reranking algorithm (e.g., Reciprocal Rank Fusion (RRF) or Cross-Encoder) to reorder the combined results based on their relevance to the user query.
- Generate Final Response: Use the LLM to generate the final response based on the reranked results and the original query.
Retriever and Generator Enhancements
Regarding RAG's two main components, the Retriever and Generator, if your RAG isn't performing well despite query and index improvements, consider optimizing these components.
Here are some architectural options for their enhancement; let’s start with retriever enhancement:
1. Retriever: Sentence Window Retrieval
In a traditional RAG system, the document chunk sent to the LLM is like a giant, panoramic view around a specific piece of information.
This broader window ensures the LLM gets a comprehensive context but can sometimes overwhelm it with excess detail.
The Sentence Window Retrieval technique introduces a more focused approach: it treats the document chunk used for embedding retrieval and the chunk provided to the LLM as distinct entities.
Think of it like having a detailed map (the embedding chunk) and a zoomed-in view (the context window) of the area you're interested in.
Workflow for Sentence Window Retrieval
- Retrieve Embedding Chunk: Extract a chunk of the document based on embedding similarity.
- Determine Context Window: Define a context window size for additional information around the retrieved chunk.
- Retrieve Expanded Window: Obtain the extended context window from the document.
- Provide Context to LLM: Pass the extended context window and the retrieved chunk to the LLM for processing.
- Adjust Window Size: Fine-tune the window size based on specific business needs to balance context and relevance.
This method is advantageous when you need to balance the richness of information with the clarity of focus, ensuring that the LLM is guided by relevant context without being overwhelmed.
2. Retriever: Metadata Filtering
Meta-data Filtering involves refining the retrieved documents by applying filters based on metadata attributes, such as time, category, or other relevant criteria.
Workflow for Metadata Filtering
- Retrieve Initial Documents: Obtain documents based on the initial retrieval process.
- Apply Metadata Filters: Filter the retrieved documents using metadata attributes (e.g., date range, category). So, when inserting them, add these metadata to the filter.
- Refine Document Set: Narrow down the document set to match the specific criteria of the query.
- Provide Filtered Documents to LLM: Pass the filtered documents to the LLM to generate a response.
By filtering metadata, not only can retrieval be enhanced, but costs can also be reduced by significantly decreasing the number of documents that need to be processed by the LLM.
The following section will focus on techniques to manage and minimize costs effectively.
3. Generator: Compressing
Retrieved document chunks often contain noise and irrelevant details that can hinder the accuracy of the LLM's responses.
Additionally, the limited prompt window of LLMs constrains the amount of context that can be processed.
To address this, compressing the prompt involves filtering out irrelevant information, highlighting key paragraphs, and reducing the overall length of the context provided to the LLM.
Workflow for Compressing
- Identify Key Information: Analyze retrieved document chunks to identify and extract essential details and critical paragraphs.
- Filter Out Noise: Remove or compress irrelevant or redundant information that does not contribute to the final answer.
- Adjust Context Length: Trim the overall length of the context to fit within the LLM's prompt window constraints, ensuring only the most pertinent information is included.
- Format and Provide Prompt: Prepare the compressed context as the LLM prompt, focusing on clarity and relevance.
- Generate Response: Use the refined prompt to generate a more accurate and focused response from the LLM.
4. Generator: Adjusting Chunk Order
LLMs tend to give more weight to information at the beginning and end of documents, often neglecting content in the middle.
To address this, we can strategically rearrange the order of retrieved document chunks.
By placing chunks with higher confidence or relevance at the start and end of the prompt and positioning those with lower confidence in the middle, we improve the LLM's focus on crucial information.
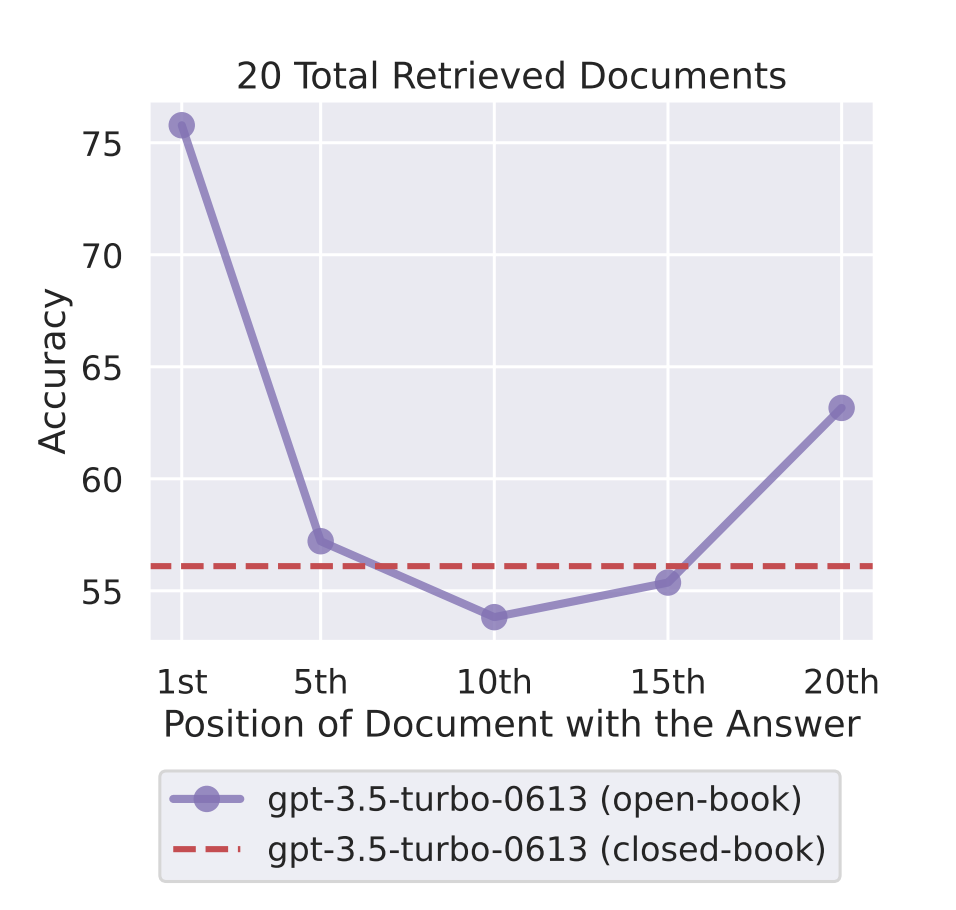
Fig 4: The Significance of Document Placement: Insights from the Research Paper "Lost in the Middle"
Workflow for Adjusting Chunk Order:
- Retrieve Document Chunks: Obtain multiple document chunks based on the query.
- Assess Chunk Confidence: Evaluate the confidence level or relevance of each chunk.
- Reorder Chunks: Arrange the chunks so those with higher confidence are positioned at the beginning and end of the prompt, with lower-confidence chunks in the middle.
- Prepare the Prompt: Assemble the reordered chunks into the LLM prompt, ensuring a logical and practical presentation of information.
- Generate Response: Use the reordered prompt to generate a response, aiming for improved accuracy and relevance based on the strategically adjusted chunk order.
Now that we have explored the various architectures of RAG, it's essential to consider the best practices for selecting the most suitable RAG for your specific requirements.
If your generator pipeline is not performing up to the mark, it seems like this article is for you.
Best Practices for Choosing the Right RAG Architecture
The architecture of RAG can be tailored based on the query type.
The following table provides an overview of how the query type influences the choice of RAG components and the rationale behind each selection:
Query Type | Recommended RAG Technique | Why This Technique Fits |
Broad, Cross-Domain Query | Hypothetical Questions | Effective in bridging gaps between diverse domains by generating relevant hypothetical questions that span across different topics. |
Complex, Multi-Faceted Query | HyDE (Hypothetical Document Embeddings) | Simulated documents provide a comprehensive view, enhancing accuracy when dealing with complex comparisons or analyses. |
Detail-Oriented Query Needing Specific Context | Sentence Window Retrieval | Offers precise context control, ensuring that relevant details are highlighted without overwhelming the LLM with too much information. |
Large Dataset Query | Hierarchical Indexing | Efficiently filters through large datasets by first narrowing down based on summaries, making it ideal for extensive searches. |
Query Needing Top Results from Multiple Angles | Hybrid Retrieval and Reranking | Combines different retrieval methods to bring in diverse perspectives, then reranks for the most relevant results. |
Time-Specific or Categorical Query | Metadata Filtering | Narrowing down results based on metadata makes focusing on specific time periods, categories, or other filters easier. |
Query Requiring Summarization | Compressing the LLM Prompt | Reduces noise and emphasizes critical points, making it ideal for summarizing large amounts of data into concise answers. |
Complex Query with Important Points at the Beginning and End | Adjusting Chunk Order | Strategically reorders content to ensure the LLM focuses on the most critical information, particularly useful when the middle content is less relevant. |
Further decisions on RAG may also depend on cost and accuracy. Enhancements like hybrid retrieval and reranking improve precision but may increase the computational load.
Similarly, compressing the LLM prompt reduces context size and computational cost while reducing the accuracy.
These practices serve as a reference but ultimately revolve around the specific use case and the problem.
It’s always nice to strike a balance between the metrics that you care about: accuracy, cost, and performance.
Common Problems Solved by Enhanced RAG Architectures
The advanced RAG techniques not only improve retrieval accuracy, but these architectures also solve common challenges, including:
- Addressing Cross-Domain Asymmetry: Cross-domain asymmetry refers to the challenge that arises when there is a mismatch between the domains or contexts of the query and the information stored in the database or knowledge base. Techniques like Hypothetical Questions and HyDE (Hypothetical Document Embeddings) tackle this by generating simulated queries or documents that align more closely with the content, reducing the reliance on direct vector matching.
- Reducing Latency: Latency can be a massive setback for a RAG app user. It can get worse in scenarios where retrieval is from massive datasets. Techniques, such as Metadata filtering and Sentence Window Retrieval, can significantly reduce the number of documents relevant to the LLM context.
- Improving Accuracy: Engineers have more control over the retrieval component when dealing with RAG. The better the retrieval from the databases, the better the generation. Techniques, such as Hybrid Retrieval and Reranking, optimize retrieval by combining multiple methods and reranking results based on relevance.
- Handling Complex Queries: Complex queries and large datasets pose challenges in managing context and accuracy. Sentence Window Retrieval improves focus by providing a more targeted context around relevant chunks. Hierarchical Indexing organizes data into manageable layers, enhancing retrieval efficiency.
- Improving Cost: Metadata Filtering reduces the number of documents processed by applying metadata-based filters, lowering computational costs. Adjusting Chunk Order and Compressing the LLM Prompt also contribute to cost savings by ensuring that only the most relevant information is processed, reducing the computational resources required.
Conclusion
The importance of Retrieval-Augmented Generation (RAG) cannot be overstated in modern information retrieval tasks. With tools available, anyone can create a RAG system.
Despite its potential, a basic RAG system is frequently hindered by several challenges. These include inaccurate query matching, handling large datasets, and managing computational costs.
This article explores architectures for RAG that offer improved performance and lower costs. HyDE, Metadata Filtering, and Sentence Window Retrieval address cross-domain asymmetry and reduce computational costs.
Hybrid Retrieval improves accuracy, and Hierarchical Indexing handles complex queries in large datasets. These advanced RAGs are impressive but are always restricted to the use case of the problem you are solving.
Collaborating with users on such problems is suggested. This is where Athina AI comes in.
Athina AI is a platform for AI teams to prototype, experiment, and monitor LLM-powered applications. Your product becomes fully performant when you act on the user's feedback, which requires the observability that Athina provides.
Sign up today to see what’s going on with your AI applications.


