Attention Is All You Need

Original Paper: https://arxiv.org/abs/1706.03762
By: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
Abstract:
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. Thebest-performingg models also connect the encoder and decoder through an attention mechanism.
We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train.
Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU.
On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.0 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature.
We show that the Transformer generalizes well to other tasksby successfullyy applying it to English constituency parsing with large and limited training data.
Summary Notes
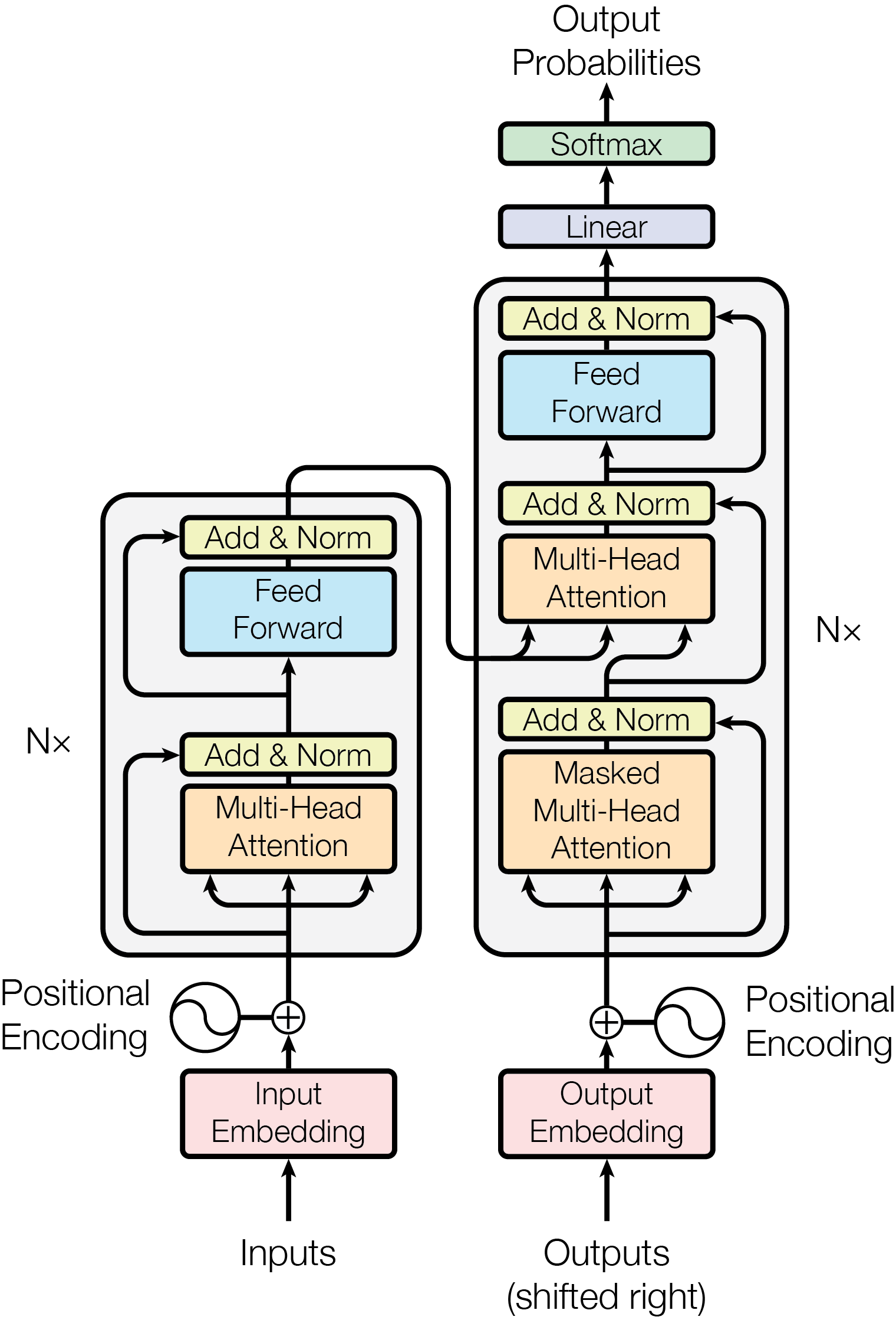
Figure 1 The Transformer - model architecture.
Introduction
Imagine a world where machines translate languages or summarize texts faster and more accurately than ever.
We are already living in it, thanks to the ground-breaking Transformer model introduced in the research paper "Attention Is All You Need" by Ashish Vaswani et al.
This blog post will demystify how Transformers, which rely solely on attention mechanisms, are setting new benchmarks in the field of sequence transduction tasks such as machine translation and language modeling.
Methodologies: The Nuts and Bolts of the Transformer
The Transformer model represents a significant departure from traditional sequence transduction models, which typically rely on recurrent neural networks (RNNs) or convolutional neural networks (CNNs).
Here's a breakdown of the key methodologies that make the Transformer unique:
- Self-Attention Mechanism:
- Unlike RNNs that process data sequentially, Transformers use self-attention mechanisms to process all input positions in parallel. This allows the model to consider the entire sequence simultaneously, making it more efficient.
- The self-attention mechanism computes a representation of the input sequence by relating different positions within the same sequence. This is achieved using scaled dot-product attention, where the dot products of the queries with all keys are computed, scaled by the square root of the dimension of the keys, and passed through a softmax function to obtain weights.
- Multi-Head Attention:
- Instead of using a single attention function, the Transformer employs multiple attention heads. Each head projects the queries, keys, and values into different subspaces, performs attention separately, and then concatenates the results. This allows the model to capture various aspects of the dependencies in the sequence.
- Formally, Multi-Head Attention is defined by the equation:[\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W^O]where each head is computed as:[\text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)]
- Positional Encoding:
- Since Transformers do not inherently understand the order of sequence elements, positional encodings are added to the input embeddings. These encodings use sine and cosine functions of varying frequencies, allowing the model to incorporate the position of each token in the sequence.
- Since Transformers do not inherently understand the order of sequence elements, positional encodings are added to the input embeddings. These encodings use sine and cosine functions of varying frequencies, allowing the model to incorporate the position of each token in the sequence.
- Feed-Forward Networks:
- Each layer in the Transformer includes a fully connected feed-forward network, applied identically to each position. This consists of two linear transformations separated by a ReLU activation.
- Each layer in the Transformer includes a fully connected feed-forward network, applied identically to each position. This consists of two linear transformations separated by a ReLU activation.
Key Findings: Achieving State-of-the-Art Results
The Transformer model's innovative architecture has led to remarkable results in various sequence transduction tasks:
- Machine Translation:
- On the WMT 2014 English-to-German translation task, the Transformer achieved a BLEU score of 28.4, outperforming previous models, including ensembles, by over 2 BLEU points.
- For the WMT 2014 English-to-French task, it set a new state-of-the-art BLEU score of 41.8, training for just 3.5 days on eight GPUs.
- Efficiency:
- The Transformer can be trained significantly faster than RNN-based models. For example, it reached state-of-the-art translation quality in just 12 hours of training on eight P100 GPUs.
- The Transformer can be trained significantly faster than RNN-based models. For example, it reached state-of-the-art translation quality in just 12 hours of training on eight P100 GPUs.
Implications and Applications
The implications of the Transformer's success are far-reaching:
- Parallelization:
- One of the most significant advantages of the Transformer is its ability to parallelize computations, making it faster and more efficient, especially for long sequences.
- One of the most significant advantages of the Transformer is its ability to parallelize computations, making it faster and more efficient, especially for long sequences.
- Versatility:
- Beyond machine translation, the Transformer shows promise in other tasks such as text summarization, constituency parsing, and potentially even in areas like image and video processing.
- Beyond machine translation, the Transformer shows promise in other tasks such as text summarization, constituency parsing, and potentially even in areas like image and video processing.
- Interpretable Models:
- The attention mechanism provides insights into how the model makes decisions, potentially making it easier to debug and understand compared to traditional RNNs.
- The attention mechanism provides insights into how the model makes decisions, potentially making it easier to debug and understand compared to traditional RNNs.
Conclusion
The Transformer model represents a monumental shift in how we approach sequence transduction tasks. By leveraging attention mechanisms exclusively, it has set new benchmarks in efficiency and performance.
As we continue to explore and expand its applications, the Transformer is poised to revolutionize not just natural language processing, but a wide array of fields requiring sequence modeling.


