Training Language Models to Self-Correct via Reinforcement Learning

Original Paper: https://arxiv.org/abs/2409.12917
By: Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, Aleksandra Faust
Abstract:
Self-correction is a highly desirable capability of large language models (LLMs), yet it has consistently been found to be largely ineffective in modern LLMs.
Existing approaches for training self-correction either require multiple models or rely on a more capable model or other forms of supervision.
To this end, we develop a multi-turn online reinforcement learning (RL) approach, SCoRe, that significantly improves an LLM's self-correction ability using entirely self-generated data.
To build SCoRe, we first show that variants of supervised fine-tuning (SFT) on offline model-generated correction traces are insufficient for instilling self-correction behavior.
In particular, we observe that training via SFT either suffers from a distribution mismatch between the training data and the model's own responses or implicitly prefers only a certain mode of correction behavior that is often not effective at test time.
SCoRe addresses these challenges by training under the model's own distribution of self-generated correction traces and using appropriate regularization to steer the learning process into learning a self-correction strategy that is effective at test time as opposed to simply fitting high-reward responses for a given prompt.
This regularization prescribes running a first phase of RL on a base model to generate a policy initialization that is less susceptible to collapse and then using a reward bonus to amplify self-correction during training.
When applied to Gemini 1.0 Pro and 1.5 Flash models, we find that SCoRe achieves state-of-the-art self-correction performance, improving the base models' self-correction by 15.6% and 9.1% respectively on the MATH and HumanEval benchmarks.
Summary Notes
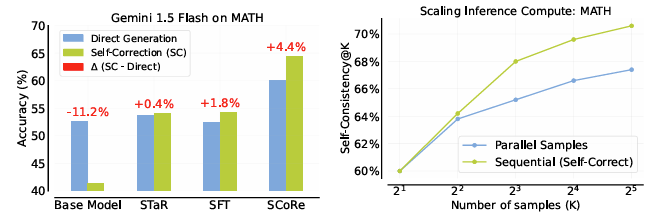
Left: SCoRe achieves state-of-the-art self-correction performance on MATH
Right: SCoRe inference-time scaling: spending samples on sequential self-correction becomes more effective than only on parallel direct samples
Introduction
In the rapidly evolving field of artificial intelligence, large language models (LLMs) serve as the backbone for many applications such as code generation and mathematical problem-solving.
However, these models often struggle with self-correction, an essential skill for autonomously refining their outputs.
The research paper "Training Language Models to Self-Correct via Reinforcement Learning" introduces SCoRe, a novel reinforcement learning-based framework aimed at endowing LLMs with effective self-correction capabilities.
Methodologies: The SCoRe Framework
The crux of SCoRe's methodology lies in its multi-turn reinforcement learning (RL) approach, which leverages self-generated data.
Unlike traditional supervised fine-tuning (SFT) methods that suffer from distribution mismatches and limited correction modes, SCoRe ensures that models learn from their own distribution of responses.
This is achieved through two main stages:
- Stage I - Initialization: This stage focuses on training a model initialization that biases the second attempt towards high-reward revisions while maintaining the first attempt close to the base model's output. This is done by optimizing an objective that penalizes deviations in the first attempt using KL-divergence regularization.
- Stage II - Multi-Turn RL with Reward Shaping: Equipped with the robust initialization from Stage I, the model undergoes multi-turn RL. This stage introduces a reward shaping mechanism that incentivizes corrections between attempts by applying a reward bonus to changes that correct errors.
Key Findings and Results
SCoRe demonstrates remarkable improvements in self-correction capabilities across various benchmarks:
- On the MATH benchmark, SCoRe improved self-correction performance by 15.6% from the base model, achieving a significant positive self-correction rate.
- In coding tasks evaluated on HumanEval, SCoRe exhibited a 12.2% increase in accuracy between attempts, outperforming traditional methods significantly.
- The model's ability to self-correct was further validated through its performance on MBPP-R, an offline repair task, where it surpassed baseline models by considerable margins.
Implications and Applications
The implications of SCoRe extend far beyond academic benchmarks.
By addressing the inherent distribution mismatches and the tendency of models to favor minimal edits, SCoRe sets a precedent for training models that can autonomously refine their outputs.
This has potential applications in:
- Autonomous Code Repair: Enabling models to improve their code outputs iteratively without human intervention.
- Enhanced Problem-Solving: Equipping LLMs with the ability to refine mathematical proofs or logical deductions autonomously.
- Efficient Learning Systems: Reducing the need for oracle feedback and allowing models to learn more efficiently from their mistakes.
Conclusion
SCoRe represents a significant leap forward in the quest to develop self-correcting LLMs.
By leveraging a structured RL framework and innovative reward shaping techniques, it overcomes the limitations of traditional training paradigms.
As we continue to explore and refine this approach, the potential for creating more autonomous, reliable, and intelligent systems becomes ever more tangible.
Encouragingly, the research also opens new avenues for future work, such as extending the framework to support multiple rounds of self-correction and exploring the integration of more granular supervision during training.
In summary, SCoRe not only enhances the self-correction capabilities of LLMs but also sets a new standard for training sophisticated, self-improving AI systems.


