Top 5 Open Source Data Scraping Tools for RAG


As LLMs continue to revolutionize industries, their role in powering Retrieval-Augmented Generation (RAG) systems has gained significant attention. A key challenge in RAG workflows is the efficient and accurate ingestion of diverse data sources into LLMs, a process that directly impacts the system’s performance and reliability. Developers and researchers need reliable tools to seamlessly process diverse data sources and optimize LLM performance.
In this article, We discuss five exceptional open-source tools that simplify data scraping and stand out for their practicality and impact.
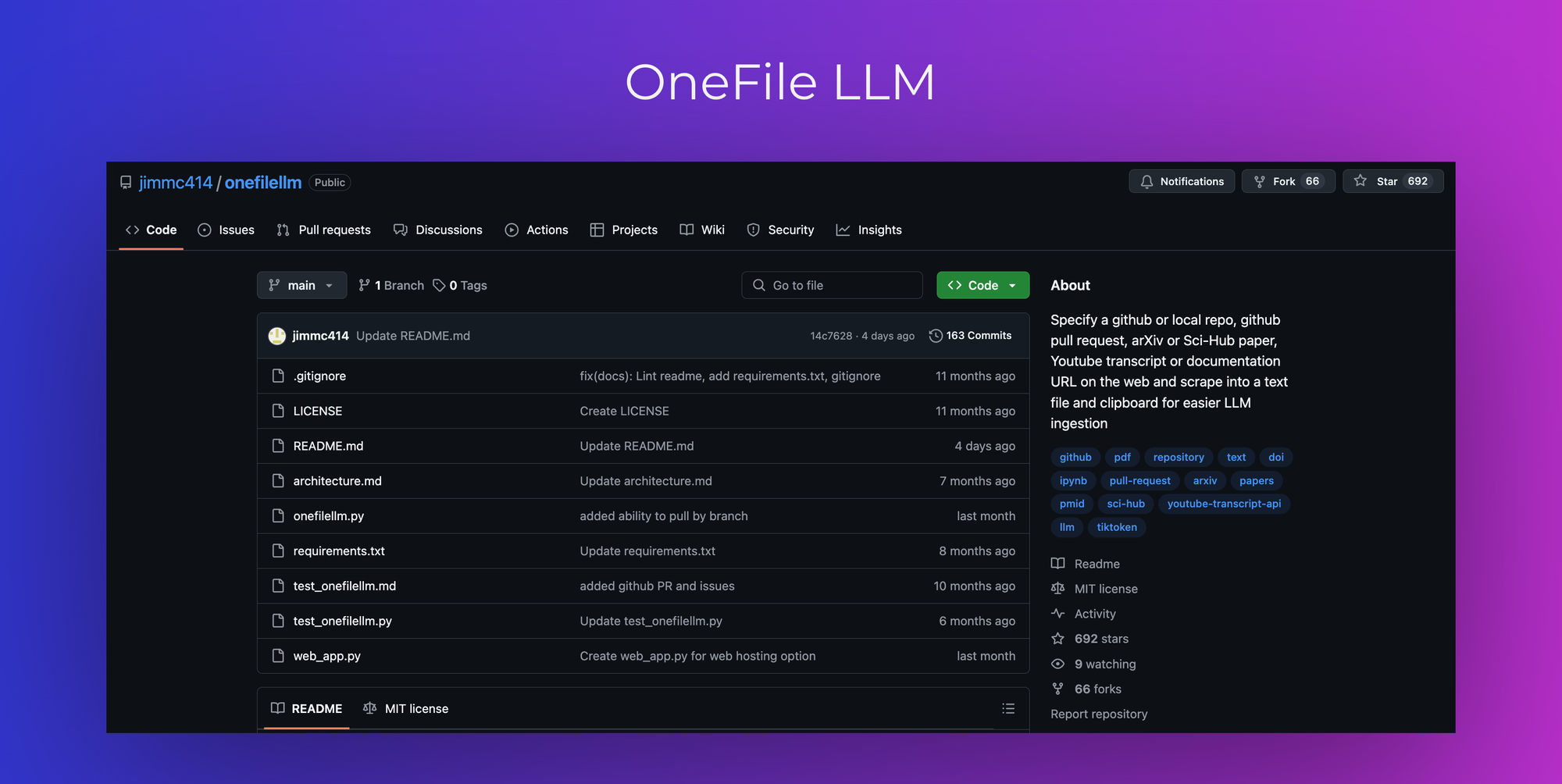
1. OneFileLLM
OneFileLLM is a command-line utility designed to aggregate and preprocess data from various sources into a single text file, facilitating seamless ingestion by LLMs.It automatically detects the type of source—be it a local file, GitHub repository, academic paper, YouTube transcript, or web documentation URL—and processes it accordingly. The consolidated output is then copied to the clipboard for immediate use.
Key Features:
-- Automatic Source Detection: Identifies and processes different data sources without manual intervention.
-- Support for Multiple Formats: Handles local files, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, and web URLs.
-- Clipboard Integration: Copies the aggregated text directly to the clipboard, streamlining the workflow.
Use Case:
OneFileLLM is particularly useful for developers and researchers who need to compile information from multiple sources into a cohesive format for LLM training or prompting. Its ability to handle diverse data types makes it a versatile tool in the LLM ecosystem.
2. Firecrawl
Firecrawl is a web scraping tool that extracts content from websites and converts it into clean markdown, ready for LLM ingestion. It crawls all accessible subpages, even without a sitemap, and handles dynamic content rendered with JavaScript. Firecrawl is open-source and integrates with various tools and workflows.
Key Features:
-- Comprehensive Crawling: Accesses all subpages of a website, ensuring thorough data extraction.
-- Dynamic Content Handling: Processes JavaScript-rendered content, capturing data that traditional scrapers might miss.
-- Markdown Output: Provides clean, well-formatted markdown suitable for LLM applications.
Use Case:
Firecrawl is suited for developers needing to ingest comprehensive website data into LLMs, particularly when dealing with complex, dynamic web pages. Its ability to handle JavaScript-heavy sites expands its applicability.

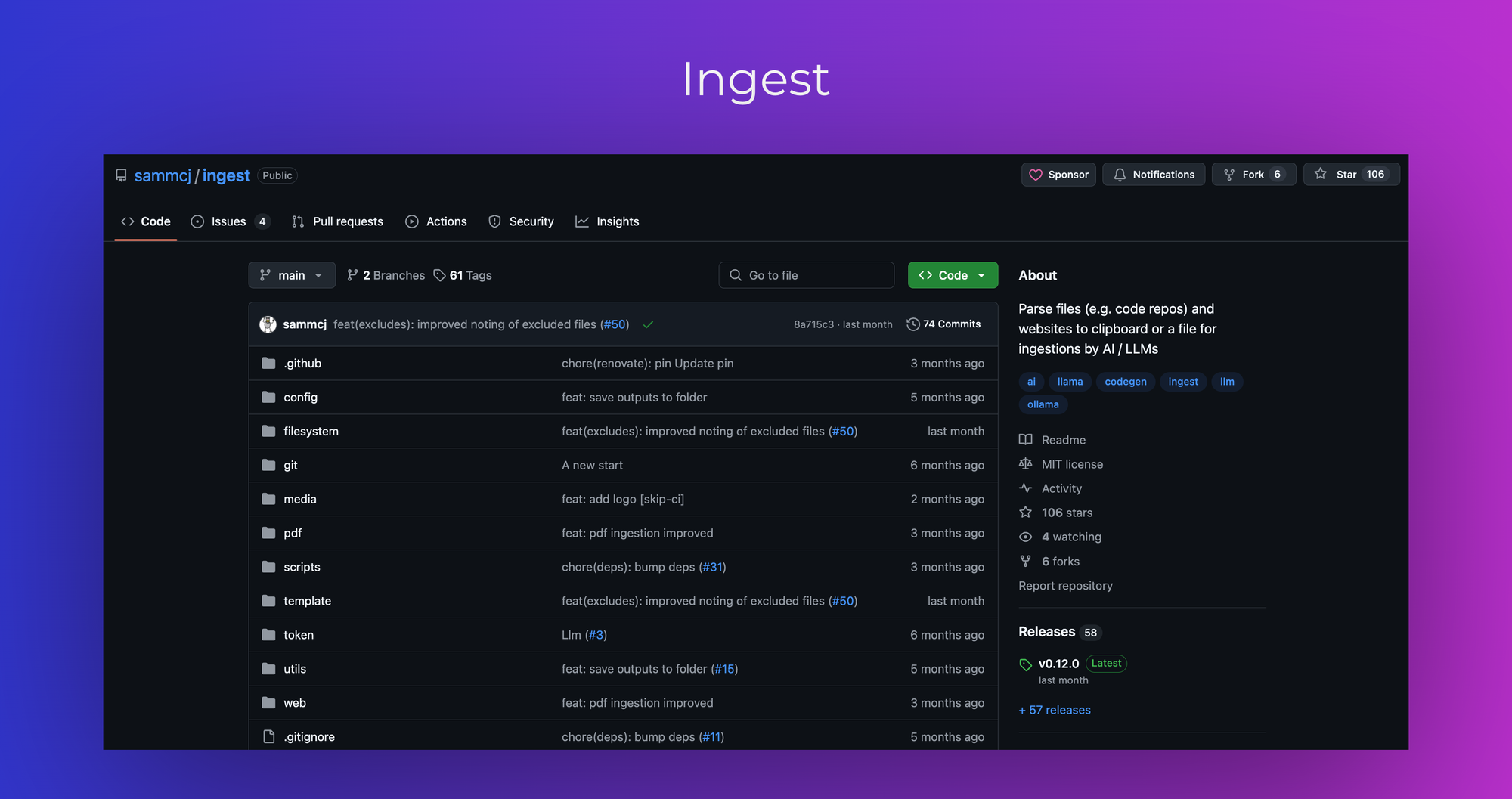
3. Ingest
Ingest is a tool that parses directories of plain text files, such as source code, into a single markdown file suitable for LLM ingestion. It traverses directory structures, generates a tree view, and includes or excludes files based on glob patterns. Ingest can also pass the prompt directly to an LLM for processing.
Key Features:
-- Directory Traversal: Navigates through directory structures to compile data.
-- File Inclusion/Exclusion: Allows specification of files to include or exclude based on patterns.
-- LLM Integration: Can directly interface with LLMs for immediate processing of the ingested data.
Use Case:
Ingest is ideal for developers looking to prepare large codebases or document repositories for LLM processing. Its ability to structure and format data into markdown enhances compatibility with various LLMs.
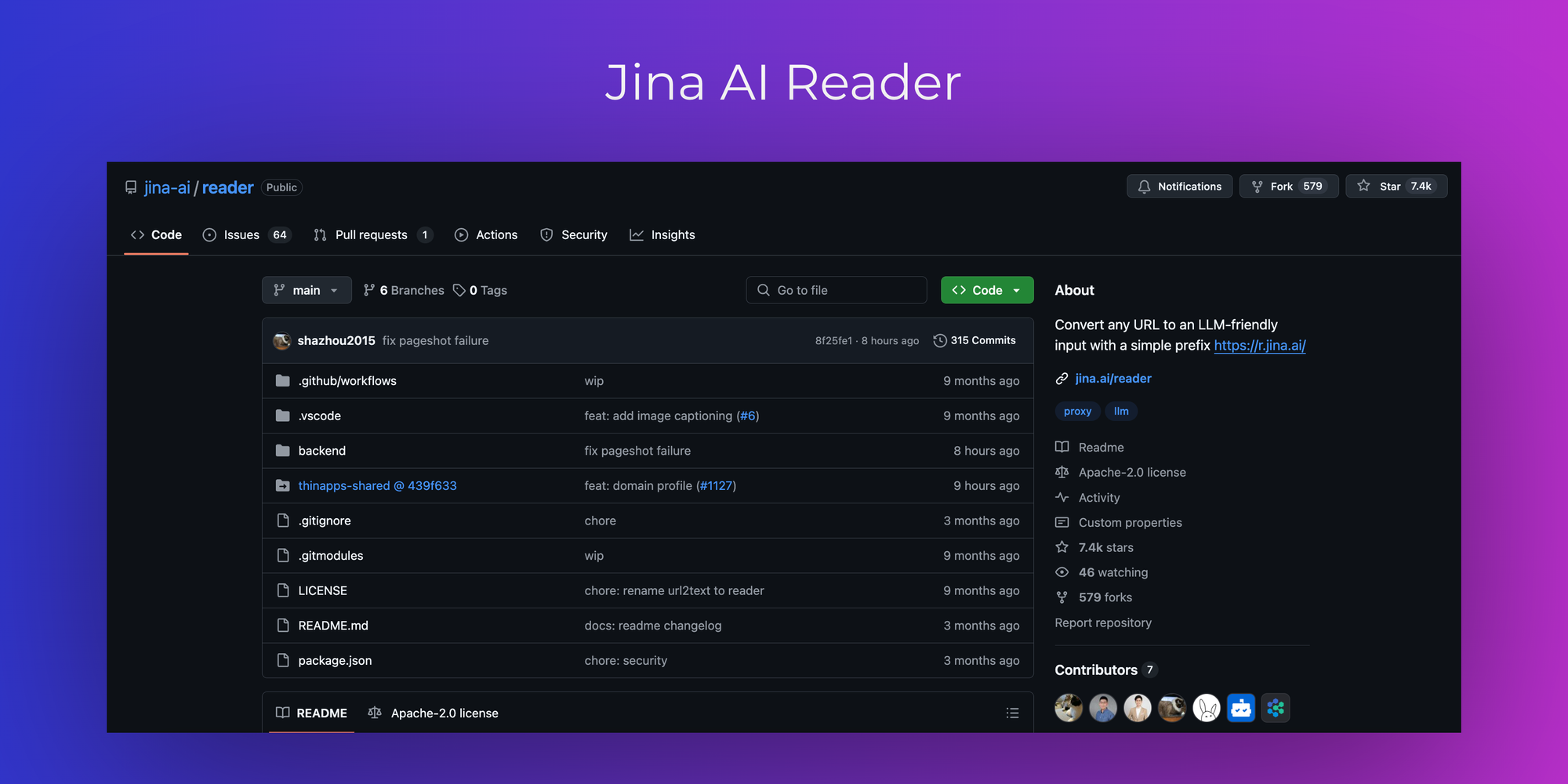
4. Jina AI Reader
Jina AI's Reader is a tool that converts any URL into an LLM-friendly input by simply prefixing the URL with https://r.jina.ai/. It cleans and structures web content, making it suitable for LLM consumption. Additionally, it offers a search functionality that returns the top five web results in a clean format.
Key Features:
-- URL Conversion: Transforms web pages into clean, structured text suitable for LLMs.
-- Web Search Integration: Provides a search endpoint that delivers top web results in an LLM-friendly format.
-- Adaptive Crawling: Recursively crawls websites to extract the most relevant pages.
Use Case:
Jina AI Reader is beneficial for applications requiring real-time web data ingestion into LLMs, such as chatbots or information retrieval systems. Its straightforward URL conversion simplifies the integration process.
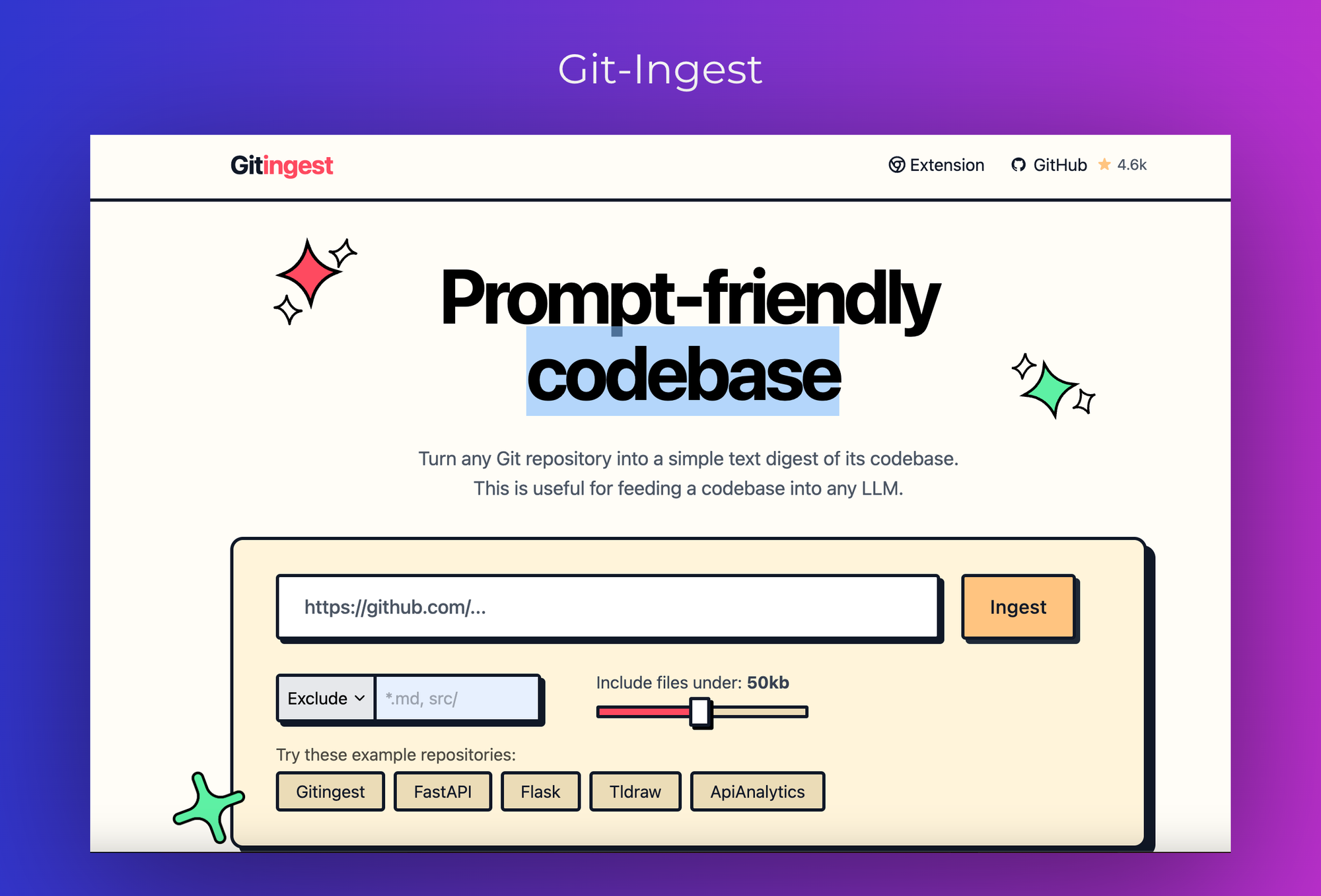
5. Git Ingest
Git Ingest is a tool that transforms Git repositories into prompt-friendly text formats, facilitating their ingestion by LLMs. By replacing 'hub' with 'ingest' in any GitHub URL, users can obtain a text digest of the codebase. This functionality is also available through a Chrome extension.
Key Features:
-- Simple URL Modification: Converts GitHub URLs into text digests by altering the URL structure.
-- Browser Integration: Offers a Chrome extension for convenient access.
-- File Size Filtering: Allows inclusion of files under a specified size, optimizing the output.
Use Case:
Git Ingest is ideal for developers and researchers who need to analyze or process codebases with LLMs. Its straightforward URL modification and browser integration streamline the ingestion process.
Conclusion
Efficient data scraping is essential for creating high-performing RAG systems, ensuring your LLMs receive the structured, relevant data they need. If you're looking to build your own unstructured RAG system on your data, check out our blog post for a step-by-step cookbook to guide you through the process.
For even more resources, explore over 10+ RAG cookbooks available on our GitHub repository. These comprehensive guides are designed to help you streamline your workflows and unlock the full potential of your RAG implementations.


