Top Benchmarks to Evaluate LLMs for Code Generation


From creating code snippets to debugging and program optimisation, Large Language Models (LLMs) have made amazing progress helping with software development. However, to evaluate their practical value, assessing these models calls for thorough benchmarking. Several benchmarks have been created to evaluate an LLM's capacity to manage programming assignments, therefore guaranteeing that these models are not only producing functionally sound solutions but also syntactically valid code.
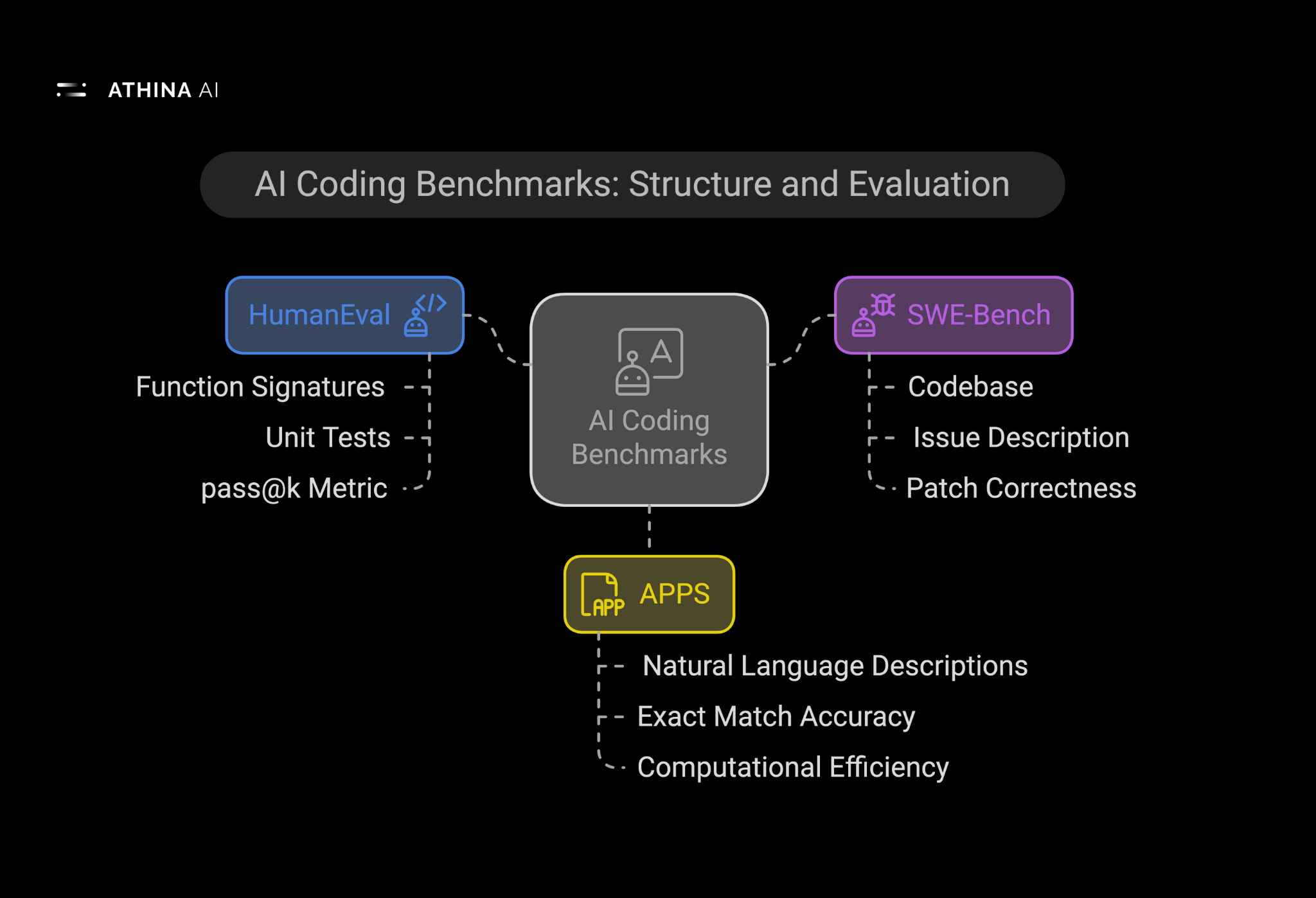
In this article, we’ll explore three of the most widely used benchmarks for evaluating LLMs in coding: HumanEval, SWE-Bench, and APPS. Each benchmark has a unique approach to assessing different facets of coding proficiency, including problem-solving, real-world patching, and adherence to best programming practices.
1. HumanEval: Testing Code Generation and Execution
HumanEval, introduced by OpenAI, is one of the most recognized benchmarks for evaluating code generation capabilities. It consists of 164 programming problems, each containing a function signature, a docstring explaining the expected behavior, and a set of unit tests that verify the correctness of generated code.
How It Works
Each problem presents a coding task that an LLM needs to complete by generating a function that passes predefined test cases. The function signature provides constraints, ensuring that the model understands the expected input and output. The goal is to assess whether the model can produce functionally correct and executable code.
Evaluation Metrics
HumanEval primarily uses the pass@k metric, which measures the probability that at least one of the model’s top k generated solutions successfully passes all test cases. For instance, pass@1 measures how often the model's first attempt at generating code is correct, while pass@10 accounts for cases where a correct solution is found among the top 10 attempts.
Strengths:
- Directly evaluates functional correctness.
- Uses unit testing, a standard software engineering practice, for verification.
- Covers a variety of problem types, from basic algorithmic challenges to more complex logic-based tasks.
Limitations:
- Limited real-world applicability since the tasks are isolated functions rather than complete programs.
- Some problems can be solved with memorization rather than true problem-solving skills.
2. SWE-Bench: Assessing Real-World Bug Fixing
Unlike HumanEval, which tests the ability to generate code from scratch, SWE-Bench focuses on a more practical aspect of software development: fixing real-world bugs. This benchmark is built on actual issues sourced from open-source repositories, making it one of the most realistic assessments of an LLM’s coding ability.
How It Works
SWE-Bench provides a codebase, an issue description, and the corresponding bug fix. The LLM is given the same context that a developer would have, including:
- The issue’s description (from GitHub issues or bug trackers).
- The code that contains the bug.
- Expected modifications to fix the issue.
The goal for the LLM is to generate a patch that resolves the issue without introducing new bugs.
Evaluation Metrics
SWE-Bench evaluates models based on:
- Patch correctness: Does the proposed fix resolve the issue?
- Code integration: Is the patch seamlessly integrated into the existing codebase without breaking functionality?
- Efficiency of fixes: Are the fixes optimized and do they follow best coding practices?
Strengths:
- Based on real-world software issues, making it highly practical.
- Tests how well an LLM can understand and modify existing code, a critical software engineering skill.
- Encourages models to develop debugging capabilities, a crucial aspect of coding.
Limitations:
- Requires contextual understanding of entire projects, which some LLMs struggle with.
- Harder to automate evaluation since correctness isn’t as simple as passing test cases.
- May have subjective elements, as different fixes might be valid but vary in style or efficiency.
3. APPS: A Diverse Benchmark for Programming Challenges
The Automated Programming Progress Standard (APPS) is one of the most comprehensive coding benchmarks. Developed by researchers at Princeton University, APPS contains 10,000 coding problems sourced from platforms like Codewars, AtCoder, Kattis, and Codeforces.
How It Works
APPS categorizes problems into different difficulty levels, from basic scripting tasks to advanced algorithmic challenges. Each problem comes with:
- A natural language description of the task.
- Example inputs and expected outputs.
- Constraints and requirements.
The benchmark assesses how well an LLM can understand problem statements, devise algorithms, and generate correct implementations.
Evaluation Metrics
- Exact Match Accuracy: Measures whether the generated code produces the exact expected output.
- Pass Rate: Similar to HumanEval’s pass@k metric, it evaluates whether a correct solution appears in a set of generated responses.
- Computational Efficiency: Some evaluations also consider runtime performance and memory usage.
Strengths:
- Covers a wide range of problem difficulties, making it more robust than single-task benchmarks.
- Tests problem-solving skills, not just code generation.
- Well-suited for evaluating an LLM’s ability to tackle competitive programming-style challenges.
Limitations:
- Less focused on real-world software engineering compared to SWE-Bench.
- Does not assess how well an LLM integrates code into larger systems.
- Some problems might be solvable using pattern recognition rather than true reasoning.
Conclusion: Choosing the Right Benchmark
Each of these benchmarks serves a distinct purpose when evaluating LLMs for coding tasks:
- HumanEval is ideal for measuring function correctness and simple algorithmic reasoning.
- SWE-Bench provides a real-world debugging and patching evaluation.
- APPS is best for testing an LLM’s ability to solve diverse and complex programming challenges.
The best evaluation strategy for an LLM depends on the intended use case. If the goal is to assist in competitive programming, APPS is the most suitable. If the focus is on real-world bug fixing and integration, SWE-Bench is more relevant. For basic function-level code generation, HumanEval remains a strong choice.
While open-source benchmarks provide valuable insights into LLM performance, they may not always be sufficient for organizations requiring customized evaluations tailored to their specific needs. This is where Athina AI comes in—a powerful LLM evaluation platform designed to help enterprises build, test, and monitor AI-driven coding solutions, ensuring their models meet the highest standards of accuracy and efficiency.


