What are the Key Metrics for LLM Evaluation?


Organizations increasingly deploy Large Language Models (LLMs) across applications, making effective evaluation crucial. While these models excel at language processing, assessing their performance poses unique challenges that traditional methods struggle to address.
Language evaluation of LLMs faces three critical challenges. First, while LLMs can generate grammatically flawless text, they may produce contextually irrelevant content or factual inaccuracies. Second, developing evaluation datasets requires specialized expertise, as automated systems cannot capture the nuances of human language. Third, evaluation frameworks must continuously adapt to evolving language patterns and cultural contexts.
Metrics are tools for measuring model performance, identifying weaknesses, and ensuring quality. Well-designed metrics detect issues like bias, inaccuracies, and inconsistencies before deployment.
Their reliability is critical as LLMs integrate into business operations and user interactions. Inadequately evaluated LLMs endanger companies’ reputations, raise ethical concerns, and incur financial loss. Therefore, businesses must prioritize systematic evaluation processes to ensure effective and reliable deployment.
Accuracy and Performance Metrics
LLM accuracy evaluation requires complementary metrics that address different performance aspects, falling into three categories:
- Core accuracy measurements
- Text similarity assessments
- Semantic similarity evaluations
Core Accuracy Metrics
Core accuracy metrics measure LLM’s ability to predict language patterns. Cross-entropy loss quantifies the difference between predicted and actual text probabilities. Lower cross-entropy indicates more accurate predictions. For instance, when completing "The cat sat on the ___," models with low cross-entropy loss favor contextually appropriate words like "mat" or "floor."
Perplexity builds upon cross-entropy to measure model uncertainty. It shows the number of words the model considers at each prediction step. A perplexity of 4 indicates the model selects from four options. Lower perplexity suggests more focused predictions, though optimal values vary by task. For example, creative writing may benefit from higher perplexity, while technical documentation requires lower perplexity.

Text Similarity Metrics
Text similarity metrics function as mathematical tools that quantify the match between two text pieces. These metrics compare AI-generated content with human-written reference texts to evaluate output quality and accuracy.
BLEU (Bilingual Evaluation Understudy) scores serve as quality indicators in translation tasks by examining n-gram overlap between translated output and reference texts. When translating "La maison bleue" to "The blue house," BLEU compares the n-grams in candidate and reference translations, assigning a numerical score based on their overlap.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) metrics focus on information retention, particularly in summarization tasks. These metrics measure how effectively a generated summary captures essential information from source text. For instance, in news article summaries, ROUGE evaluates whether the original's key facts and main points appear in the condensed version.
METEOR (Metric for Evaluation of Translation with Explicit ORdering) enhances similarity assessment through semantic understanding. It recognizes different words that can convey identical meanings, which proves valuable when evaluating text where writers might use various terms to express the same concept, such as "automobile" and "car."
Levenshtein metric measures the minimum number of single-character edits (insertions, deletions, and substitutions) needed to transform one string into another. The Levenshtein ratio provides a quantitative measure of textual similarity and difference. For example, changing "analyze" to "analysis" requires specific character modifications.
Implementation:
- Installation:
Before using these text similarity metrics, install the required packages:
!pip install evaluate nltk python-Levenshtein rouge_scoreNecessary Imports and Downloads:
To use these metrics effectively, we first need to import the necessary libraries and download the required NLTK data. NLTK requires specific datasets for tokenization and word processing.
import evaluate
import nltk
from nltk.translate.meteor_sore import meteor_score
from Levenshtein import ratio
nltk.download(“punkt”)
nltk.download(“punkt_tab”)
nltk.download(“wordnet”)- BLEU and ROUGE Score Calculation
BLEU and ROUGE metrics compare candidate text against references. BLEU uses n-gram overlap, while ROUGE focuses on sequence matching.
bleu_metric = evaluate.load("bleu")
rouge_metric = evaluate.load("rouge")
reference = ["the blue house"]
candidate = ["the blue house"]
bleu_results = bleu_metric.compute(predictions=candidate, references=reference)
print(f"BLEU Score: {bleu_results['bleu'] * 100:.2f}")
rouge_results = rouge_metric.compute(predictions=candidate, references=reference)
print(f"ROUGE-1 F1: {rouge_results['rouge1']:.2f}")
print(f"ROUGE-L F1: {rouge_results['rougeL']:.2f}")Output:

- METEOR Score Calculation
METEOR handles synonyms and word order variations by tokenizing text and computing scores based on aligned words.
reference = ["the automobile is parked"]
candidate = ["the car is parked"]
reference_tokenized = [nltk.word_tokenize(ref) for ref in reference]
candidate_tokenized = nltk.word_tokenize(candidate[0])
meteor_score = meteor_score(reference_tokenized, candidate_tokenized)
print(f"METEOR Score: {meteor_score:.2f}")Output:
- Levenshtein Similarity Calculation
Levenshtein similarity measures character-level edit distance between strings, which is useful for comparing similar words or phrases.
text1 = "analyze"
text2 = "analysis"
levenshtein_similarity = ratio(text1, text2)
print(f"Levenshtein Similarity: {levenshtein_similarity:.2f}")Output:

3. Semantic Similarity Metrics
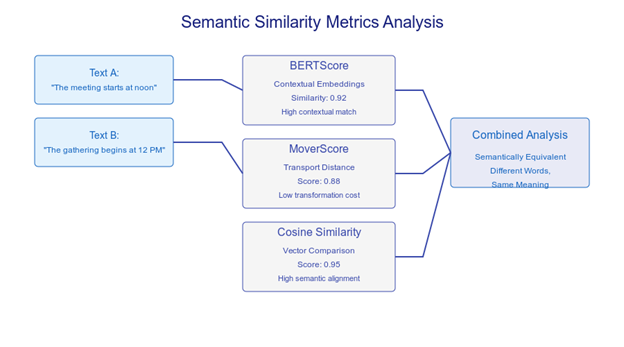
Semantic similarity metrics evaluate text alignment based on meaning rather than exact wording. By analyzing core messages and context, these tools identify relationships between text passages.
BERTScore, for instance, leverages BERT models to analyze context-dependent meaning through word representations. It transforms words into numerical values reflecting their contextual relationships. When comparing "The medical procedure was successful" with "The operation achieved its intended outcome," BERTScore recognizes semantic equivalence despite varied vocabulary.
MoverScore applies transport theory principles to calculate semantic distances using numerical word representations. It measures the computational effort needed to transform one text's meaning into another. The metric quantifies semantic relationships between phrases like "The project deadline approaches" and "The submission date draws near" through mathematical distance calculations.
Cosine similarity measures semantic relationships between text representations on a -1 to 1 scale, where 1 indicates identical meaning. It converts text into numerical vectors, enabling precise meaning comparison. For example, phrases like "Revenue increased this quarter" and "Sales grew in Q3" receive high cosine similarity scores due to their semantic equivalence.
Implementation:
- Installation:
To use these metrics, you'll need to install the required packages:
!pip install bert_score moverscore sentence-transformers scikit-learn torch pytorch-pretrained-bert sentencepiece pyemd transformers- Necessary imports and downloads
These imports set up our environment for using pre-trained models and computing various similarity scores.
from bert_score import score
from moverscore import word_mover_score
from collections import defaultdict
from moverscore import get_idf_dict
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np- BERTScore Calculation
Here, we initialize BERTScore with BERT's base uncased model, which computes precision, recall, and F1 scores by comparing contextual embeddings.
candidate = ["The medical procedure was successful"]
reference = ["The operation achieved its intended outcome"]
Scorer = BERTScorer(model_type="bert-base-uncased")
P, R, F1 = Scorer.score(candidate, reference)
print(f"BERTScore F1: {F1.mean():.4f}, BERTScore Precision: {P.mean():.4f}, Recall: {R.mean():.4f}")Output:

- MoverScore calculation
MoverScore uses word embeddings and Earth Mover's Distance to compute semantic similarity between texts. Here's how to calculate it:
candidate = ["The medical procedure was successful"]
reference = ["The operation achieved its intended outcome"]
Scorer = BERTScorer(model_type="bert-base-uncased")
P, R, F1 = Scorer.score(candidate, reference)
print(f"BERTScore F1: {F1.mean():.4f}, BERTScore Precision: {P.mean():.4f}, Recall: {R.mean():.4f}")Output:
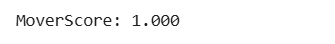
- Cosine Similarity:
This code loads SentenceTransformer's MiniLM model to create sentence embeddings and then uses cosine similarity to measure semantic relatedness.
model = SentenceTransformer('all-MiniLM-L6-v2')
text1 = "Revenue increased this quarter"
text2 = "Sales grew in Q3"
embeddings1 = model.encode([text1])
embeddings2 = model.encode([text2])
similarity = cosine_similarity(embeddings1, embeddings2)
print(f"Cosine Similarity: {similarity[0][0]:.3f}")Output:

Content Quality Metrics
Content quality assessment for LLMs evaluates outputs without reference texts and verifies factual correctness. These metrics ensure high-quality content generation when perfect references don't exist.
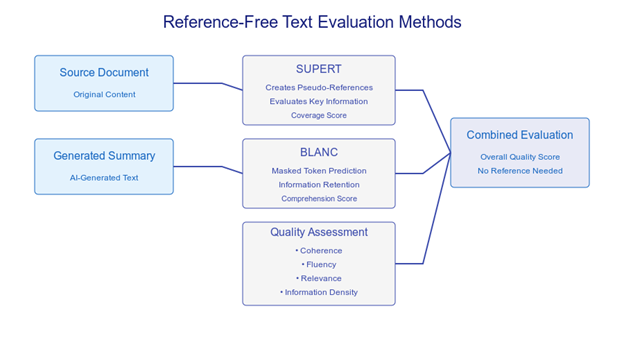
Reference-Free Evaluation
Modern LLMs generate content without relying on direct comparison references. To address this, SUPERT (Summarization Evaluation with Pseudo-References Technique) compares summaries with pseudo-references from source documents. This method measures information capture effectiveness without human-written references.
BLANC (BLANk-based evaluation of Comprehensiveness) evaluates generated text quality by testing how well it helps reconstruct masked tokens in source documents. BLANC assesses information retention by measuring how accurately generated summaries predict the hidden words from the original text.
The quality-based assessment examines coherence, fluency, and relevance directly from the generated text. This approach analyzes linguistic patterns and discourse structure to evaluate content quality independently, without reference comparisons.
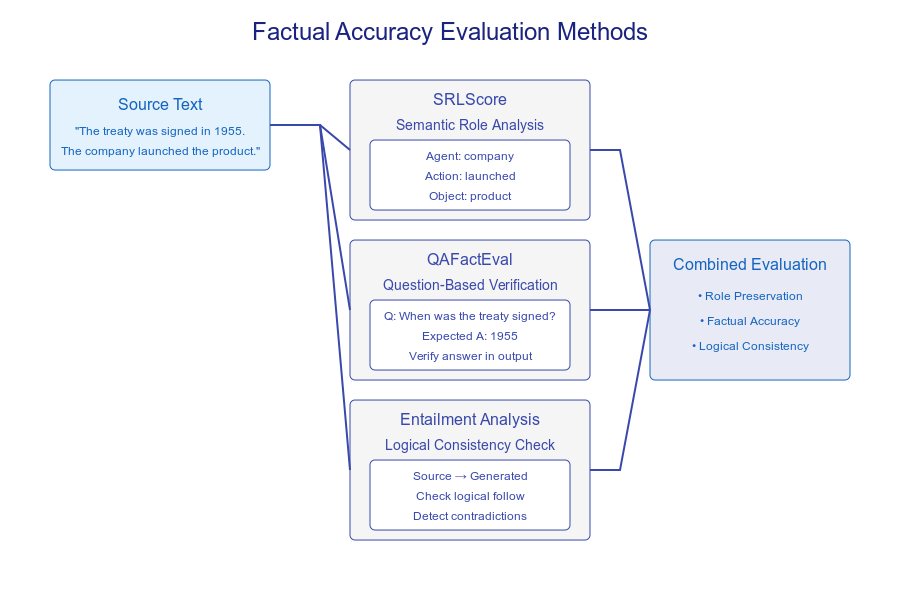
Factuality Assessment
Ensuring factual accuracy is a significant challenge in LLM evaluation. SRLScore analyzes semantic role relationships in generated text, verifying proper connections between actions, agents, and objects. It confirms whether statements like "The company launched the product" maintain accurate relationship structures.
QAFactEval generates questions based on source text and assesses whether the model output provides accurate answers. This approach verifies fact preservation in generated content. For instance, when a source states, "The treaty was signed in 1955," QAFactEval checks whether the generated text maintains this date's accuracy.
Entailment-based metrics determine the logical consistency of the generated content with the information. These metrics detect contradictions and unsupported claims by checking if each statement in the output can be reasonably inferred from the source material. This helps catch subtle factual inconsistencies that might slip through other evaluation methods.
Other Evaluation Methods
LLM evaluation combines human-like judgment with practical performance considerations to create comprehensive assessment frameworks.
Advanced Judgment Frameworks
The LLM-as-Judge framework uses language models to evaluate other models' outputs across coherence, relevance, and accuracy dimensions. Prompt-based techniques test specific capabilities, while Multiple Evidence Calibration gathers several performance examples to reduce individual variations. Balanced Position Calibration controls for biases in prompt ordering.
Performance Efficiency Metrics
Response latency tracks output generation speed—critical for real-world applications where users expect quick responses. Resource utilization metrics monitor CPU, GPU, and memory usage to help plan infrastructure needs. Computational efficiency analysis finds an optimal balance between model capability and operational costs.
Fairness and Ethical Metrics
LLM deployments require rigorous fairness and bias evaluation to ensure equitable service across all users while upholding ethical principles.
Bias Detection Methodologies
Word Embedding Association Tests (WEAT) analyze model outputs for unconscious biases by comparing concept associations. This method reveals embedded biases by examining how models link concepts. For example, if a model consistently associates "nurse" with feminine terms and "engineer" with masculine ones, it indicates bias.
Demographic Fairness Measures
These metrics evaluate model performance consistency across population groups, tracking response quality and accuracy. Mathematical measures like demographic parity and equal opportunity quantify performance differences. A model fails fairness standards if it provides detailed technical explanations to one group while offering simplified responses to another.
Ethical Consideration Frameworks
These frameworks assess outputs against responsible AI principles by examining:
- Content safety and appropriateness
- Privacy protection measures
- AI limitation transparency
- Cultural sensitivity
Human-in-the-Loop (HITL)
HITL evaluation integrates human judgment to identify subtle biases that automated metrics might overlook. Trained evaluators assess:
- Cultural nuances
- Contextual appropriateness
- Potential harm
- Fair treatment across groups
This human oversight strengthens automated fairness metrics and improves bias detection methods.
Implementation Guidelines
To evaluate LLMs effectively, organizations need structured approaches that combine multiple metrics and maintain consistent monitoring practices. Here's how to implement comprehensive evaluation protocols.
Comprehensive Evaluation Strategies
Integrate evaluation throughout the development cycle. Create baseline frameworks, including:
- Performance benchmarks for specific tasks
- Acceptance criteria for outputs
- Testing protocols for use cases
- Regular evaluation schedules
Multiple Metric Integration
Combine metrics for complete performance insight:
- Accuracy metrics for basic capabilities
- Content quality measures for output relevance
- Fairness metrics for ethical operation
- Efficiency metrics for resource optimization
For example, a customer service chatbot requires ROUGE scores for accuracy, latency measurements for speed, and bias detection for fairness.
Continuous Monitoring Protocols
Establish systems that:
- Track real-time performance
- Alert teams to unusual behavior
- Collect user feedback
- Monitor resource consumption
Documentation Requirements
Maintain records of:
- Evaluation methodologies
- Benchmark results and trends
- Performance thresholds
- Mitigation strategies
- Model behavior changes
These records enable progress tracking, decision justification, and quality maintenance throughout the model lifecycle.
LLM Benchmarks
Selecting appropriate benchmarks helps organizations effectively evaluate their LLM implementations against industry standards. Let's explore how to choose and use these benchmarks strategically.
Understanding LLM Benchmarks
LLM benchmarks serve as standardized tests measuring model performance across distinct capabilities. For instance, MMLU (Massive Multitask Language Understanding) evaluates knowledge spanning 57 subjects from mathematics to law, while HellaSwag tests common-sense reasoning abilities.
Key Benchmarks Overview
- MMLU: Tests knowledge across academic and professional fields
- HellaSwag: Measures common sense understanding
- BBH: Evaluates complex reasoning and problem-solving
- TruthfulQA: Tests accuracy and misinformation resistance
Benchmark Categories
- Reasoning and Commonsense
- BIG-bench Hard (BBH) challenges models through complex reasoning tasks requiring multi-step logical deduction.
- Language Understanding and QA
- These benchmarks evaluate comprehension and question-answering abilities. SuperGLUE measures understanding across different linguistic tasks, while SQuAD tests reading comprehension.
- Coding
- Coding benchmarks assess the model's ability to understand and generate programming solutions. HumanEval and MBPP test practical coding skills across different programming languages.
- Conversation and Chatbots
- MultiWOZ tests task-oriented dialogue capabilities, while PersonaChat evaluates casual conversation skills.
Limitations and Solutions
Benchmarks have inherent limitations:
- It may not reflect real-world usage patterns
- It can become outdated as technology advances
- It might be vulnerable to optimization tricks
Organizations increasingly supplement standard benchmarks with synthetic data testing to address these limitations and create more relevant evaluation scenarios.
Conclusion
LLM evaluation evolves rapidly, requiring sophisticated assessment approaches. Organizations must select metrics that align with their needs while ensuring responsible AI development.
Modern evaluation integrates performance metrics with qualitative methods. BLEU and ROUGE measure technical accuracy, while LLM-as-Judge evaluates nuanced language understanding. This combined approach builds more reliable, ethically sound AI systems.
Looking ahead, LLM evaluation priorities include:
- Advanced semantic understanding and bias detection
- Real-time performance monitoring and adaptation
- Stronger alignment between technical capabilities and human values


